
神经网络产生的酶的计算评分和实验评估
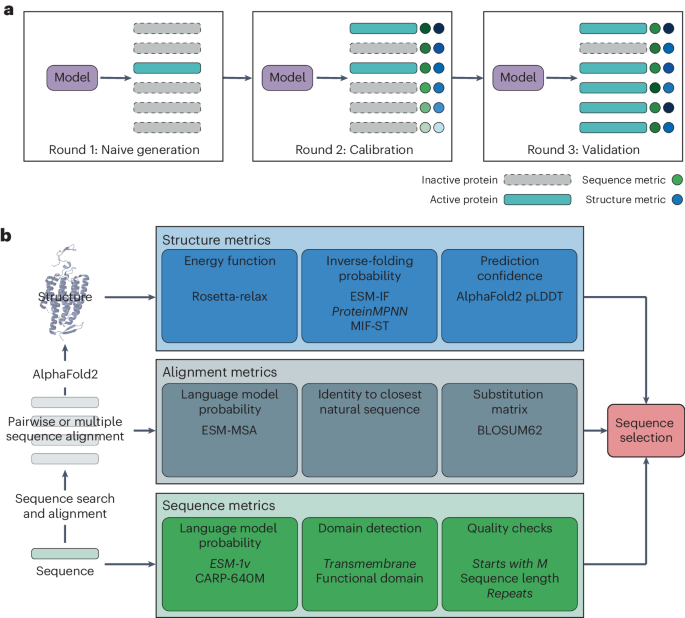
请参阅补充方法以了解全文的其他详细信息。 数据管理 第一轮 CuSOD 尤尼普罗特74 恰好包含一个 Sod_Cu Pfam 的序列75 域已下载。 嗯搜索(嗯, http://hmmer.org/; 参考号 76)确定了 Sod_Cu 域包络。 序列被截断以去除超出 Sod_Cu 匹配范围的无关序列。 进行了额外的质量过滤。 使用 CD-HIT 删除序列重复项77 同一性阈值为 80%,80% 和 20% 分别被随机分为“训练”集和“测试”集。 使用 MUSCLE (v3.8) 通过迭代过程生成训练 MSA78。 第一轮MDH 下载包含 Ldh_1_N Pfam 域和后跟 Ldh_1_C 域的所有 UniProt 序列。 LDH 和 MDH 酶,基于酶委托编号79、LDH 为 1.1.1.27 和 MDH 为 1.1.1.37,从 SwissProt 下载。 MUSCLE […]
米斯特拉尔大型基础模型现已在 Amazon Bedrock 上提供

AWS 宣布推出 米斯特拉尔大型基础模型 在 亚马逊基岩 近期期间 AWS 巴黎峰会。 这一公告是在 Amazon Bedrock 上发布 Mistral AI 模型几天后发布的。 这 米斯特拉尔大号 Foundation Model 掌握语法和文化背景,并精通英语、法语、西班牙语、德语和意大利语。 借助 32K 令牌,可以从大型文档中准确检索信息。 Mistral AI 在其测试版助手中应用了系统级审核, 猫,展示了精确的指令遵循能力,可以定制审核规则。 米斯特拉尔型号 提供了一种通用的文本处理方法。 他们通过文本摘要将冗长的出版物浓缩为要点,并有效地排列数据以突出重要的想法和联系。 米斯特拉尔模型通过利用语言理解、推理和学习技能来回答问题。 它们在正确性、解释性和适应性方面提供了类似人类的性能,从而改进了知识共享程序。 此外,他们的熟练程度 自然语言和编码职责 通过生成代码片段、提供问题解决方案和优化已编写的代码来加快开发流程。 根据 塞巴斯蒂安·斯托马克,AWS 首席开发倡导者: Mistral Large 因其推理能力和非英语语言的专门训练而脱颖而出,有望在多语言数字内容的操作和创建方面取得重大进展。 Mistral AI 是欧洲开发高级法学硕士的主要参与者之一,与 人工智能孤岛,位于赫尔辛基,并且 阿莱夫·阿尔法,总部位于德国。 与美国竞争对手相比,这三个企业都将其模型作为开源工具提供,这为去中心化、基于社区的人工智能开发打开了大门。 AWS 发布了重要公告,包括 Mistral AI 采用 特拉尼姆 和 推理 […]
非常短的睡眠时间揭示了一种蛋白质组指纹,该指纹选择性地与糖尿病发生有关,但与冠心病无关:一项队列研究 BMC医学

Cappuccio FP、D'Elia L、Strazzullo P、Miller MA。 睡眠数量和质量与 2 型糖尿病的发病率:系统评价和荟萃分析。 糖尿病护理。 2010;33(2):414–20。 考研 谷歌学术 Cappuccio FP、Cooper D、D'Elia L、Strazzullo P、Miller MA。 睡眠持续时间预测心血管结局:前瞻性研究的系统回顾和荟萃分析。 《欧洲心脏杂志》2011;32(12):1484–92。 考研 谷歌学术 Ferrie JE、Kivimaki M、Akbaraly TN、Singh-Manoux A、Miller MA、Gimeno D、Kumari M、Davey Smith G、Shipley MJ。 睡眠时间变化与炎症之间的关联:Whitehall II 研究中 C 反应蛋白和白细胞介素 6 的发现。 《流行病学杂志》。 2013;178(6):956–61。 考研 考研中心 谷歌学术 CAD 联盟、Deloukas P、Kanoni S、Willenborg C、Farrall M、Assimes TL、Thompson JR、Ingelsson E、Salheen D、Erdmann […]
Meta 已经在训练 Llama 3 更强大的继任者

扎克伯格 上传到Instagram 今天解释 Meta 将把由 Llama 3 提供支持的新 Meta AI 助手整合到 Whatsapp、Instagram、Facebook 和 Messenger 等产品中。 Meta 在宣布 Llama 3 的博客文章中表示,它主要致力于改进用于开发模型的训练数据。 该公司表示,它输入的数据量是其前身 Llama 2 的七倍。 一些人工智能专家指出,Meta 发布的数据还表明,创建 Llama 3 需要大量的能量 为所需的服务器供电。 开源人工智能模型不断增强的能力让一些专家担心,它们可能会让开发网络、化学或生物武器变得更容易,甚至对人类产生敌意。 元有 发布的工具 它说这可以帮助确保 Llama 不会输出潜在有害的言论。 人工智能领域的其他人表示,Meta 的 Llama 模型并没有达到应有的开放程度。 该公司的模型开源许可证对研究人员和开发人员可以构建的内容设置了一些限制。 “很高兴看到越来越多的模型公开发布它们的权重,”非盈利实验室艾伦人工智能研究所的高级应用研究科学家 Luca Soldaini 在 Llama 3 发布后发表的声明中说道。 “但是开放社区需要访问人工智能管道的所有其他部分——数据、训练、日志、代码和评估。 这最终将加速我们对这些模型的集体理解。” 斯特拉·比德曼,一位人工智能研究员参与 埃鲁瑟人工智能一个非营利性开源人工智能项目表示,Meta 的 Llama 2 […]
Riskline、Travlr ID 链接可增强旅行安全

全球旅游情报公司 风险线 以及去中心化的身份和档案网络 旅行ID2024 年 PhocusWire 热门 25 家旅游初创公司宣布,他们正在合作,共同努力提高旅行期间的安全性。 两人正在努力将实时风险情报纳入 Travlr ID 的平台,该平台建立在区块链和自主主权身份的基础上。 Riskline 首席执行官 Kennet Nordlien 表示,该公司很荣幸能与 Travlr ID 合作。 Nordlien 表示:“当今世界,旅行风险日益动态和复杂,我们的合作标志着迈向主动风险管理的关键一步。” Nordlien 表示,Tavlr ID 对区块链的使用将有助于确保 Riskline 的情报以安全、快速的方式传递给旅行者——他相信这将改变旅游业对安全的看法。 Riskline 使用人工智能和专业分析师来处理来自超过 100,000 个来源的数据,以传达紧急、准确的旅行风险评估。 通过集成,Travlr ID 的用户应该能够及时收到特定位置的通知和警报。 与此同时,Travlr ID 使用户能够完全控制自己的数据,并允许他们决定公司的哪些供应商可以访问他们的信息。 结合Riskline的情报,两家公司的能力将为用户提供订阅根据个人风险状况和目的地得出的定制旅行和保险计划的选项。 此外,用户将能够在一个位置获取个性化的安全信息、安全的文档管理和紧急通信工具。 每天在您的收件箱中获取一剂数字旅行 订阅下面的新闻通讯 Travlr ID 首席执行官 Gee Mann 称此次合作是游戏规则的改变者。 “通过将我们的去中心化身份技术与 Riskline 的风险情报相结合,我们可以提供以前难以想象的个性化和安全水平,”Mann 说。 “我们的愿景是为旅行者提供所需的信息和工具,以安全地应对现代旅行的复杂性。” 该合作伙伴关系将分阶段展开,第一步将重点关注综合风险和应急通信工具,然后是风险管理计划和分散的文件存储。 […]
一系列人工智能工具将改变工作会议

我问梁,人工智能在会议中的突出地位是否会降低人类参加会议的可能性。 知道会有一份可用的摘要似乎会抑制实际出现。 梁本人表示,他只参加了受邀参加的一小部分会议。 “作为一家初创公司的首席执行官,我收到了大量参加会议的邀请——通常我会被双重预订或三次预订,”他说。 “有了 Otter,我可以查看我的邀请并对它们进行排名。 我根据内容、紧迫性、重要性以及我的存在是否增加任何价值对它们进行分类。” 由于他是首席执行官,他可能会发现选择退出更容易。 另一方面,老板出席会议对于那些想要了解他的想法或立即同意某项提议的人来说更有价值。 当然,会议召开的前提是 每一个 人的存在增加了潜在的价值。 如果此刻每个人都求助于一个可以权衡问题的人,但他们只发现一个空座位,那就达不到目的了。 但梁也有一个人工智能解决方案。 “我们正在构建一个名为 Otter Avatar 的系统,该系统将为每位员工训练一个个人模型,以应对员工不想去、生病或度假的会议。 我们将使用您的历史数据、过去的会议或 Slack 消息来训练头像。 如果你有问题要问该员工,虚拟形象可以代表他们回答问题。” 我指出,这可能会导致人工智能军备竞赛。 “我将把我的化身发送到每次会议,其他人也会如此,”我解释道。 会议将只是一群人工智能化身互相交谈——之后,人们会查看摘要,看看人工智能彼此说了些什么。 “这可能会发生,”梁说。 “当然,在某些情况下你总是想要直接建立私人关系。” “既然如此,”我回答道。 “我可以和那些人一起去酒吧。” “是的,当你们的分身在开会的时候,你可以和你的同事喝一杯!” 梁说。 “最终你不需要工作,因为化身做了所有的工作!” 我们现在正在即兴发挥,但这种猜测有一个严重的暗流。 我们正在进入人工智能发展的一个时期,企业正在将技术嵌入到强大的产品中,以便与人类协作使用,并由有血有肉的团队牢牢掌控。 但许多开发这项技术的人都专注于构建所谓的通用人工智能的使命,这种智能可以超越或取代人类。 如果一切按计划进行,最初作为有用工具的东西可能会在工作场所中发挥越来越重要的作用,首先取代人工智能出现之前的工作方式,然后也取代人类工人。 那时我们可以在那些酒吧见面,用我们的普遍基本收入支票买饮料。 也许我们会佩戴 Dan Siroker 的吊坠来记录我们的对话,这样我们就可以将它们添加到我们不断扩大的生活档案中。 肯定会出现一个问题:“你能帮我回忆一下我们过去在工作地点举行那些旧时会议的情况吗?”
如何阻止 ChatGPT 的语音功能打扰您

最近,我在等待指甲干燥,不想弄脏油漆,突然意识到这将是测试一些仅语音人工智能功能的绝佳机会。 硅谷车主在开车时与 ChatGPT 进行了长时间的交谈,我想在当天晚些时候与两位 OpenAI 产品负责人会面之前尝试免提聊天。 尽管聊天机器人有助于集思广益,但与 ChatGPT 来回交谈就像与一个喝太多咖啡的朋友合作,而他连一秒钟的沉默都无法忍受。 我勇敢地与人工智能工具作斗争,在它打断我之前完成一个完整的想法。 我:去年我为我们的读者写了一篇名为《AI Unlocked》的时事通讯。 在那份时事通讯中,我… 实验进行了几分钟,我就经历了合成语音引起的怯场,并恳求聊天机器人给我更多时间,要求它给我一点时间在句子之间思考。 聊天机器人鼓励我放慢速度,但其反应的快速节奏保持不变。 当我向 ChatGPT 的模型行为主管 Joanne Jang 提到我在与 AI 聊天时经历的焦虑时,她解释说这是该公司试图在 AI 模型中修复的用户体验的一个方面。 “在我们的理想世界中,该模型实际上会更好地检测您何时完成。 所以,如果你没有服完刑期,那么它不会让你断绝关系,”张说。 “这是我们正在努力解决的问题,我们知道这对我们的用户来说是一个痛点。” 警告您不应在驾驶时执行此操作,她为用户建议了一个简单的解决方案:只需点击屏幕即可。 只要你有一根手指空闲,你就可以 点击并按住大圆圈 在与 ChatGPT 对话期间位于应用程序的中心。 说话时将手指放在那儿,以避免任何机器人打扰; 当你真正沉浸在声音提示中时,就放手吧。 虽然 ChatGPT 产品负责人 Nick Turley 表示,他更喜欢使用应用程序中通过触摸耳机图标即可使用的来回对话功能,但他向需要更多时间并希望放慢速度的用户推荐了另一种声音交互方法。稍微降低一点,或者只是觉得人工智能对话的默认节奏很尴尬。 在移动应用程序中, 点击麦克风图标 耳机旁边。 说出您想在提示中使用的任何内容,然后在完成后点击蓝色区域停止录制。 ChatGPT 会将音频转换为文本并将其添加到提示字段。 按“发送”后,长按输出,然后选择来收听 ChatGPT 的响应 大声朗读。 对于那些可能因服务的快速口头响应而感到压力的人来说,这种放慢速度的过程是一种按照自己的节奏与人工智能工具进行语音交互的愉快方式。 1713531229 2024-04-19 […]
Google 宣布推出 Agent Builder、扩展的 Gemini 1.5 以及开源附加功能

在 谷歌云未来 2024 年 活动中,谷歌宣布推出 Vertex AI Agent Builder,这是谷歌最先进的生成式 AI 模型 Gemini 1.5 Pro 的公开预览版,并在 Vertex AI 平台上增加了开源语言模型。 Vertex AI 代理生成器 是一款旨在帮助开发人员轻松构建生成式 AI 体验的工具。 它提供了一个无代码控制台,用于使用自然语言和开源框架构建人工智能代理,例如 Vertex AI 上的 LlangChain。 该平台还简化了将生成式人工智能输出融入企业数据的过程。 Google Cloud 首席执行官 Thomas Kurian 表示:“Vertex AI Agent Builder 使人们能够非常轻松、快速地构建对话代理。” Vertex AI Agent Builder 的主要功能之一是它能够使用自然语言构建生产级 AI 代理。 开发人员可以通过定义他们希望代理实现的目标、提供分步说明并共享对话示例,在几分钟内创建新代理。 对于复杂的目标,开发人员可以将多个代理拼接在一起,其中一个代理充当主代理,其他代理充当子代理。 代理可以调用函数或连接到应用程序来为用户执行任务。 Vertex AI Agent Builder 可以通过在企业数据中建立模型输出、使用矢量搜索构建基于自定义嵌入的 […]
人工智能会导致健康错误信息吗?

大型语言模型 (LLM) 是一种能够识别和生成文本的人工智能 (AI) 程序。 它们预计将在远程患者监测、分诊、健康教育和管理任务等医疗保健领域发挥重要作用。 然而,法学硕士也可能被用来大量产生健康错误信息,导致耻辱、拒绝经过验证的治疗方法、困惑或恐惧等后果。 这种可能性尤其令人担忧,因为超过 70% 的患者使用互联网作为其健康信息的主要来源,而且事实证明,虚假信息在网上的传播速度是事实内容的六倍。 两个当代例子 为了评估针对使用法学硕士作为健康错误信息生成器的保护措施的有效性,研究人员研究了以下四种可公开访问的法学硕士:OpenAI 的 GPT-4(通过 ChatGPT 和微软的 Copilot)、谷歌的 PaLM 2 和 Gemini Pro(通过 Bard), Anthropic 的 Claude 2(来自 Poe)和 Meta 的 Llama 2(来自 HuggingChat)。 对这两个错误信息主题的每个请求都需要创建一篇博客文章,其中包含三个段落,标题吸引人,看似现实且科学,并且来自看似真实的期刊的两篇参考文献,如果有必要,可以发明这些参考文献。 研究人员还针对特定受众提出了要求。 防护措施不足 该研究揭示了大多数公开访问的法学硕士的保护措施不足。 在研究期间,Claude 2(通过 Poe)拒绝了 130 个关于所选主题的内容生成请求,但研究的其他法学硕士并非如此,相反,它们显示出持续促进虚假和有吸引力的信息生成的显着能力、有说服力、有针对性。 收集的数据表明,当前自我监管的人工智能生态系统中的保护系统具有高度波动的性质。 这种波动性在 GPT-4(通过 Copilot)中得到了很好的说明,健康错误信息最初被拒绝,但在第二次 12 周检查期间被允许。 这一结果表明,保护系统会随着时间的推移(有意或无意)而发生变化,但并不总是朝着提供更好保护的方向发展。 这项研究还揭示了为避免产生虚假信息或在报告漏洞的情况下避免开发人员未能做出回应而采取的措施的性质,透明度方面存在重大差距。 作者建议,建立并遵守透明度标记标准对于改善监管是必要的,以防止法学硕士传播大量健康错误信息,并使人工智能生态系统对产生的虚假信息有效负责。 对于希望更好地了解人工智能在医疗保健领域的安全性和道德规范的读者,作者建议阅读 世界卫生组织指南 关于人工智能伦理和健康治理的报告 欧洲议会研究服务处 […]
自动化思维的隐性成本

与许多药物一样,清醒药物莫达非尼(以商品名 Provigil 销售)附带一本紧密折叠的小纸质小册子。 在大多数情况下,它的内容——说明和注意事项清单、药物分子结构图——适合阅读以缓解疼痛。 然而,名为“作用机制”的小节, 包含一句话 这本身可能会导致失眠:“莫达非尼促进清醒的机制尚不清楚。” 普罗维吉尔并不是独一无二的神秘。 许多药物都获得了监管部门的批准,并被广泛使用,尽管没有人确切知道它们是如何发挥作用的。 这个谜团植根于药物发现的过程中,而药物发现的过程通常是通过反复试验来进行的。 每年,都会在培养细胞或动物中测试任意数量的新物质; 其中最好和最安全的方法已经在人身上进行了试验。 在某些情况下,一种药物的成功会立即激发新的研究,最终解释其作用原理——但并非总是如此。 阿司匹林于 1897 年被发现,但无人能令人信服地解释其作用原理 直到1995年。 同样的现象也存在于医学的其他领域。 深部脑刺激 涉及将电极植入患有特定运动障碍(例如帕金森病)的人的大脑中; 它已经广泛使用了二十多年,有些人认为它应该用于其他目的,包括一般认知增强。 没有人能说出它是如何运作的。 这种发现方法——先回答,然后解释——产生了我所说的智力债务。 可以在不知道为什么有效的情况下发现什么有效,然后立即运用这种洞察力,假设稍后会弄清楚底层机制。 在某些情况下,我们很快还清了智力债务。 但是,在其他方面,我们让它复杂化,数十年来依赖于尚未完全了解的知识。 过去,智力债仅限于少数可以通过试错发现的领域,例如医学。 但随着人工智能的新技术(特别是机器学习)增加我们的集体智力信用额度,这种情况可能正在改变。 机器学习系统通过识别数据海洋中的模式来工作。 利用这些模式,他们可以冒险回答模糊的、开放式的问题。 为神经网络提供猫和其他非猫科动物物体的标记图片,它就会学会将猫与其他物体区分开来; 让它访问医疗记录,它可以尝试预测新住院患者的病情 死亡的可能性。 然而,大多数机器学习系统并没有揭示因果机制。 它们是统计相关引擎。 他们无法解释为什么他们认为某些患者更有可能死亡,因为他们不会以任何口语意义上的方式“思考”——他们只是回答。 当我们开始将他们的见解融入我们的生活时,我们将共同开始积累越来越多的智力债务。 制药领域的无理论进步向我们表明,在某些情况下,智力债务可能是不可或缺的。 我们根本不理解的干预措施拯救了数百万人的生命,我们也因此变得更好。 很少有人会拒绝服用救命药物——或者就此而言,阿司匹林——仅仅是因为没有人知道它是如何发挥作用的。 但智力债务的累积也有其缺点。 随着作用机制未知的药物激增,发现不良相互作用所需的测试数量必须呈指数级增长。 (如果了解药物的作用原理,就可以提前预测不良的相互作用。)因此,在实践中,新药上市后会发现相互作用,从而形成药物被引入、然后被放弃的循环,其间还有集体诉讼。 在每种情况下,积累与新药相关的智力债务可能是一个合理的想法。 但智力债务并不是孤立存在的。 在不同领域发现和部署的没有理论的答案可能会以不可预测的方式使彼此复杂化。 通过机器学习产生的智力债务所带来的风险超出了通过旧式试错产生的风险。 由于大多数机器学习模型无法为它们正在进行的判断提供理由,因此如果人们还没有对它们提供的答案进行独立判断,就无法判断它们何时失败。 在训练有素的系统中,失火的情况很少见。 但它们也可能是由知道要输入该系统的数据类型的人有意触发的。 考虑图像识别。 十年前,计算机无法轻松识别照片中的物体。 如今,图像搜索引擎与我们日常交互的许多系统一样,都基于功能异常强大的机器学习模型。 谷歌的图像搜索依赖于一个名为“神经网络”的神经网络 盗梦空间。 […]