
矢量数据库公司 Qdrant 希望 RAG 更具成本效益

不要错过 VentureBeat Transform 2024 上 OpenAI、Chevron、Nvidia、Kaiser Permanente 和 Capital One 的领导者。在这场为期三天的独家活动中,获取有关 GenAI 的重要见解并扩展您的网络。 了解更多 越来越多的公司希望将检索增强生成 (RAG) 系统纳入其技术堆栈,并且改进它的新方法也正在浮出水面。 矢量数据库公司 奎德兰特 相信其新搜索算法 BM42 将使 RAG 更加高效且更具成本效益。 Qdrant 成立于 2021 年,开发了 BM42,为致力于新搜索方法的公司提供向量。该公司希望为客户提供更多混合搜索,即结合语义和关键字搜索。 Qdrant 联合创始人兼首席技术官 Andrey Vasnetsov 在接受采访时表示 创业节拍 BM42 是对算法 BM25 的更新,传统搜索平台使用该算法对搜索查询中的文档相关性进行排名。RAG 通常使用矢量数据库或将数据存储为数学指标的数据库,以便于匹配数据。 VB Transform 2024 倒计时 7 月 9 日至 11 日,欢迎企业领导者齐聚旧金山,参加我们的旗舰 AI 活动。与同行交流,探索生成式 AI 的机遇和挑战,并了解如何将 AI […]
Vectorize:利用 RAG 管道加速 AI 创新
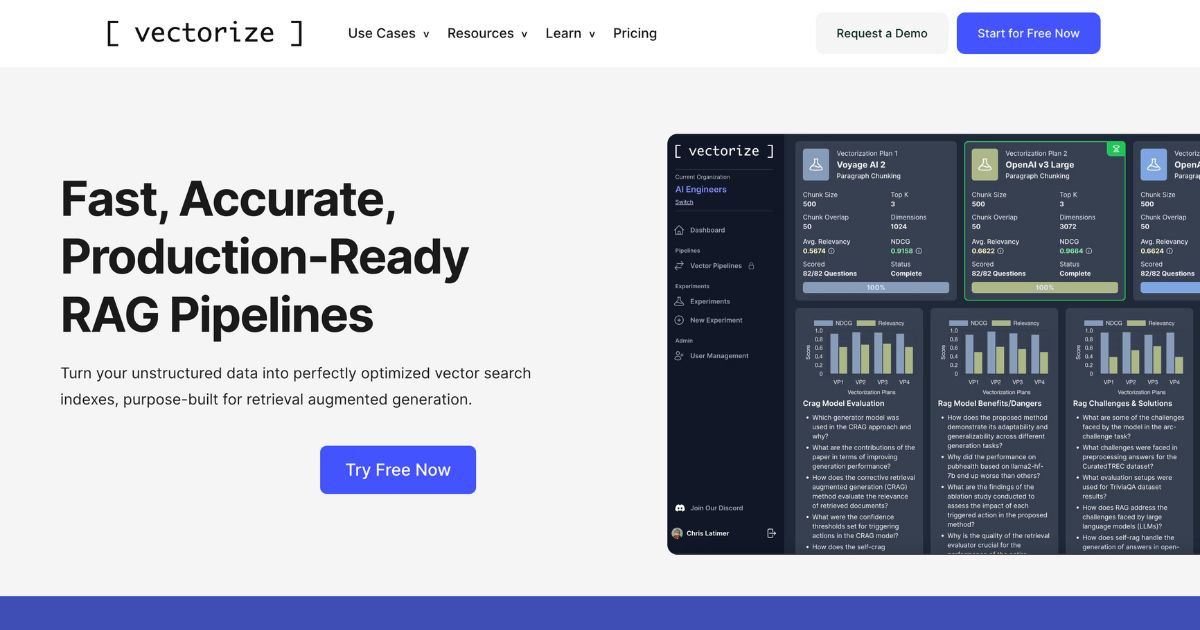
发现更多 人工智能商业工具: Vectorize 是一款功能强大的业务工具,旨在将非结构化数据转换为优化的向量搜索索引,非常适合检索增强生成。通过利用大型语言模型 (LLM) 的强大功能,Vectorize 可帮助企业通过三个简单的步骤转换数据:导入、实验和部署。 Vectorize 能够上传文档或连接到外部知识管理系统,从而提取自然语言,供 LLM 用来提高生产力和创造创新的客户体验。该平台提供各种分块和嵌入策略,让用户可以选择最合适的选项或利用平台的建议。 Vectorize 提供内置连接器,可连接到流行的知识库、协作平台、CRM 等,使企业可以轻松地从组织内的任何位置导入数据。该平台还支持顶级 AI 平台,例如 Hugging Face、Google Vertex、LangChain、AWS Bedrock、OpenAI、Microsoft Azure、Jina AI、Voyage AI 和 Mistral AI,确保用户能够访问经过验证的嵌入模型和分块策略。 此外,Vectorize 还允许企业在其首选向量数据库中自动创建和更新向量索引,从而简化保存 AI 就绪向量的过程。用户还可以通过平台的资源了解生成 AI 的最新趋势和见解。 总之,Vectorize 为希望增强 AI 能力并高效创建生成式 AI 应用程序的企业提供了全面的解决方案。借助实验、内置 AI 平台支持和自动索引等功能,Vectorize 可以帮助企业简化流程并提高生产力。 Vectorize – 功能 快速、准确、可用于生产的 RAG 管道 从组织中的任何位置导入数据 内置对顶级 AI 平台的支持 在您最喜欢的矢量数据库中自动创建和更新矢量索引 Vectorize –定价 Vectorize […]
RAG 对抗机器:将第一方数据注入 AI 模型以获得更好的结果

第一方数据长期以来一直是营销人员的工具箱中的重要工具,用于在各个媒体触点上个性化客户体验。但它尚未影响大多数公司如何使用生成式人工智能技术。 然而,专有数据集有可能在当今生成式人工智能的几个关键营销应用中发挥重要作用。其中包括大规模内容制作、活动洞察生成和客户服务。 利用检索增强生成管道 (RAG) 形式的大量结构化和非结构化数据集合的技术和流程已经存在。RAG 是一种最近开发的流程,用于提取、分块、嵌入、存储、检索并将第一方数据输入基础模型(例如 OpenAI、Google 和 Meta 提供的模型)。 以下是如何使用这些工具将第一方数据注入您下一个支持 AI 的广告系列。 一切都与背景有关 无论您使用 GPT、Dall-E、Imagen、Gemini 还是 Llama,每次您要求生成式 AI 应用程序生成文本或图像时,您都会提供(主要基于文本的)指令。这些指令被发送到模型以生成所需的响应(称为推理)。结果要么是洞察,要么是广告文案或创意。 每个营销人员和机构都可以从 Google 和 OpenAI 的 PB 级训练数据中受益,从而更有效地完成工作。不过,有一个技巧。基础模型不会经常重新训练(可能每隔一年一次)。这意味着它们并不总是最新的。虽然这些模型可能看起来无所不知,但实际上它们对特定于您的品牌和客户的信息一无所知。 为什么?因为这些信息不对外公开。 如果你要求 Dall-E 或 Imagen 针对你的五个主要受众群体分别调整主创意,他们肯定会达不到要求,甚至可能产生幻觉,因为他们不知道你的受众是谁,也不知道他们可能对什么感兴趣。 能够利用第一方数据和知识为提示提供背景信息至关重要,这不仅能让您从人群中脱颖而出,还能帮助生成式 AI 模型提供有用的结果。如果您在提示中添加特定于受众的数据(例如人口统计和偏好),那么您将以极低的成本获得符合品牌的定制创意。 同样,要求 Gemini 或 GPT 为新产品撰写 500 到 800 个字符的亚马逊产品描述不会产生很好的效果,除非您在目录中添加其他产品的现有高性能文案示例。这个过程被称为小样本提示。 订阅 AdExchanger 日报 每个工作日将我们编辑的综述发送到您的收件箱。 RAG 时间 识别和提取专有知识和数据的能力是生成成功内容的关键。但是,需要做些什么才能将第一方数据输入大型语言模型 (LLM)? 对于生成式 AI,数据管理涉及的技术和管道与其他营销技术应用(例如客户数据平台)所使用的技术和管道不同。这是因为第一方数据的性质更为广泛,以及 […]
发布 0.9.1 – UI 和应用程序中的 RAG 支持 + 流式传输修复 · helixml/helix · GitHub
补丁修复 – 0.9.1 修复了 UI 中普通推理会话的流式传输。 0.9 版本说明 我们现在在 Helix 中支持 RAG。您可以从主页上传文档并对其执行 RAG: 我们还将“推理”和“微调”切换为更通用、更用户友好的“聊天”和“学习”: 现在默认的学习模式是 RAG,因为它比微调快得多。RAG 更擅长检索具体事实,而微调更擅长回答有关上传文档的一般问题。 您仍然可以进行微调,可以从应用程序主页选择微调,也可以使用设置按钮: 您现在还可以在 Helix Apps 中指定 RAG 并微调数据源 helix.yaml 使用 RAG 数据源或微调 LLM 自定义助手。为此,运行 RAG 或微调会话,现在将创建“数据源 ID”。检索 rag_source_data_entity_id 从 RAG 会话中的信息按钮,如下所示: “rag_source_data_entity_id”: “c6cc22d3-23a6-4b2d-acdd-6f561158e0c0”, 并将其放入 helix.yaml 像这样在 GitHub 仓库中创建文件: name: My Test Helix RAG App description: This is a test […]