
使用语义缓存优化 Azure OpenAI 应用程序
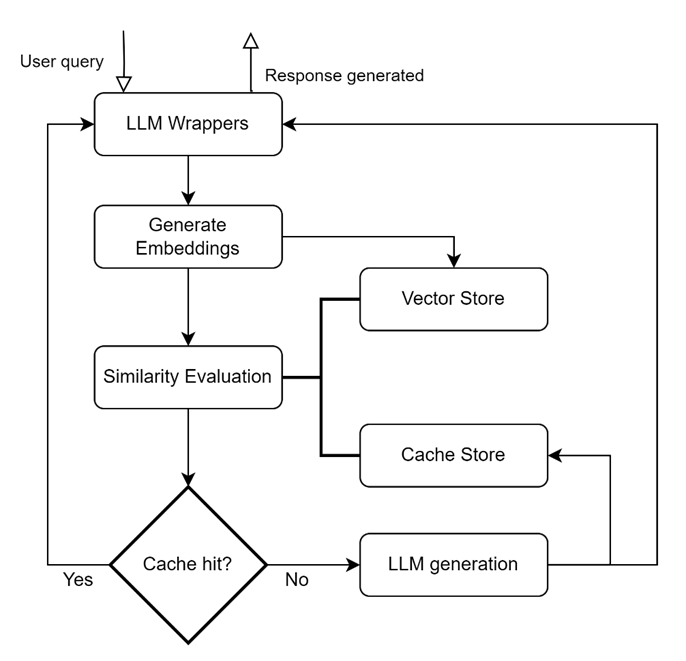
介绍 优化大型语言模型 (LLM) 成本和性能的方法之一是缓存来自 LLM 的响应,这有时称为“语义缓存”。 在本博客中,我们将讨论使用语义缓存的方法、好处、常见场景和关键注意事项。 什么是语义缓存? 缓存系统通常存储常用检索的数据,以便以最佳方式进行后续服务。 在法学硕士的背景下,语义缓存维护先前提出的问题和响应的缓存,使用相似性度量从缓存中检索语义相似的查询,并在相似性阈值内找到匹配时使用缓存的响应进行响应。 如果缓存无法返回响应,则可以从新的 LLM 调用返回答案。 语义缓存层的关键构建块: LLM 包装 用于添加集成和支持不同 LLM(Llama、OpenAI 等)的能力.,)。 生成嵌入 帮助生成用户查询的嵌入表示。 生成的嵌入通常保存在向量存储中。 A 矢量商店 用于持久化查询的嵌入并支持在查询调用时快速检索嵌入,它们可以是内存中的数据库或针对存储、索引和检索进行优化的专用向量数据库。 (例如,FAISS、Hnswlib、PGVector、Chroma、CosmosDB 等)。 缓存存储 保留来自 LLM 的响应,并在缓存命中时提供响应。 (例如 SQLite、Elasticsearch、Redis、MongoDB 等)。 相似度评估 模块使用相似性度量/距离将输入查询与基于嵌入的向量存储查询进行比较。 关键绩效指标/日志记录: 一些特定于缓存的 KPI 包括缓存命中率(缓存处理的请求/总请求)和延迟(处理要处理的查询和从缓存检索相应响应的时间)。 语义缓存的好处: 成本优化: 由于在不调用 LLM 的情况下提供响应,因此缓存响应可以带来显着的成本效益。 我们遇到过这样的用例,客户报告说,缓存层可以满足用户总查询的 20-30%。 延迟的改善: 众所周知,法学硕士在生成回复方面表现出较高的延迟。 这可以通过响应缓存来减少,只要查询是从缓存层应答的,而不是每次都调用 LLM。 缩放比例: 由于缓存命中响应的问题不会调用 LLM,因此配置的资源/端点可以自由回答用户未见过的/较新的问题。 当扩展应用程序以处理更多用户时,这会很有帮助。 […]