
介绍
优化大型语言模型 (LLM) 成本和性能的方法之一是缓存来自 LLM 的响应,这有时称为“语义缓存”。 在本博客中,我们将讨论使用语义缓存的方法、好处、常见场景和关键注意事项。
什么是语义缓存?
缓存系统通常存储常用检索的数据,以便以最佳方式进行后续服务。 在法学硕士的背景下,语义缓存维护先前提出的问题和响应的缓存,使用相似性度量从缓存中检索语义相似的查询,并在相似性阈值内找到匹配时使用缓存的响应进行响应。 如果缓存无法返回响应,则可以从新的 LLM 调用返回答案。
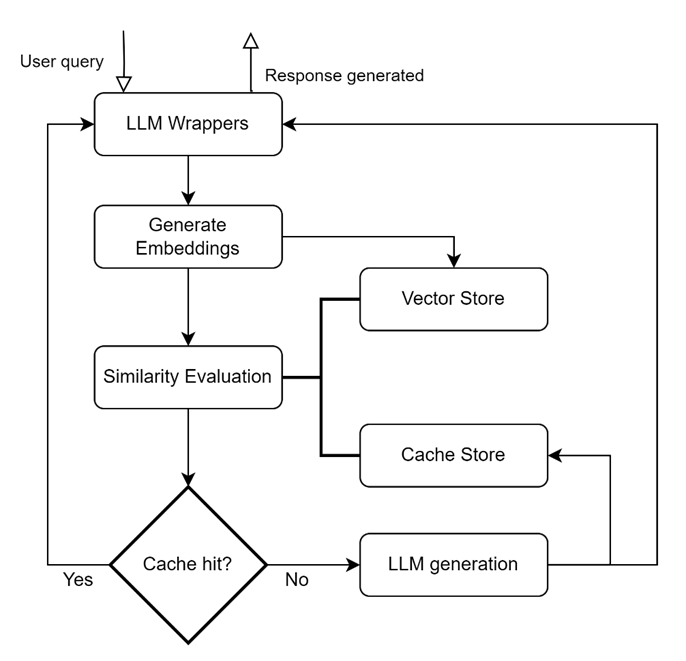
语义缓存层的关键构建块:
LLM 包装 用于添加集成和支持不同 LLM(Llama、OpenAI 等)的能力.,)。 生成嵌入 帮助生成用户查询的嵌入表示。 生成的嵌入通常保存在向量存储中。 A 矢量商店 用于持久化查询的嵌入并支持在查询调用时快速检索嵌入,它们可以是内存中的数据库或针对存储、索引和检索进行优化的专用向量数据库。 (例如,FAISS、Hnswlib、PGVector、Chroma、CosmosDB 等)。 缓存存储 保留来自 LLM 的响应,并在缓存命中时提供响应。 (例如 SQLite、Elasticsearch、Redis、MongoDB 等)。 相似度评估 模块使用相似性度量/距离将输入查询与基于嵌入的向量存储查询进行比较。
关键绩效指标/日志记录: 一些特定于缓存的 KPI 包括缓存命中率(缓存处理的请求/总请求)和延迟(处理要处理的查询和从缓存检索相应响应的时间)。
语义缓存的好处:
- 成本优化: 由于在不调用 LLM 的情况下提供响应,因此缓存响应可以带来显着的成本效益。 我们遇到过这样的用例,客户报告说,缓存层可以满足用户总查询的 20-30%。
- 延迟的改善: 众所周知,法学硕士在生成回复方面表现出较高的延迟。 这可以通过响应缓存来减少,只要查询是从缓存层应答的,而不是每次都调用 LLM。
- 缩放比例: 由于缓存命中响应的问题不会调用 LLM,因此配置的资源/端点可以自由回答用户未见过的/较新的问题。 当扩展应用程序以处理更多用户时,这会很有帮助。
- 响应的一致性: 由于缓存层根据缓存的响应进行回答,因此不涉及实际生成,并且向语义相似的查询提供相同的响应。
Azure 上实施的参考架构:

- 用户通过用户应用程序发送查询。
- 使用 AOAI 嵌入模型将查询转换为向量。
检索和响应(场景 1)
- Azure Cosmos DB 充当矢量存储,接收较新的查询并根据相似性度量检索现有查询。 注意:如果应用程序是图像检索,则图像将存储在 Blob 存储中,位置存储在矢量存储中。
- 如果基于相似性阈值命中缓存,则从缓存层检索响应(例如,可以从 Cosmos DB 存储和提供文本响应,而可以根据 Cosmos DB 中的位置从 Blob 存储提供图像)。
- 响应被提供给用户。
检索和响应(场景 2)
- 如果未命中缓存,则在 Azure AI 搜索(用于实现 RAG 系统的服务)中搜索用户查询(文本和/或矢量)。
- 检索前 K 个匹配文档并将其传递给法学硕士。
- 响应是由法学硕士根据从 Azure AI 搜索检索到的相关数据生成的。
- LLM 的响应将传递给用户。
传递到 Log Analytics 工作区的日志 – KPI(例如从缓存提供响应的次数)以及从缓存提供服务的令牌可以从持久保存到日志分析工作区的日志中获取,以供以后分析以了解缓存的影响。
查询向量存储或将查询定向到 LLM、日志记录等的编排由自定义程序或自定义现有框架(如 GPTcache 或 Langchain 或 Autogen)来处理。
实施方法:
虽然可以从头开始构建和实现逻辑,但某些现有库可以帮助加速开发。 在本节中,我们将简要介绍一些实现了语义缓存的流行开源框架。
1.GPT缓存:
GPTCache 是一个开源框架(MIT 许可证),采用嵌入算法将查询转换为嵌入,并对嵌入执行相似性搜索。 GPTCache 使用 LLM 适配器、嵌入生成器、缓存管理器、相似性评估器和后处理器作为组件。 它本质上是模块化的,支持 LLM、嵌入、向量存储和缓存存储的多种选项。 使用 GPTCache 涉及以下步骤:
- 构建你的缓存: 选择嵌入函数、相似性评估函数、数据存储位置以及驱逐策略。
- 选择您的法学硕士: GPTCache目前支持OpenAI模型和langchain框架。 Langchain 支持多种 LLM,例如 Anthropic、Huggingface 和 Cohere 模型。
以下是 GPTCache 的组件:
- pre-process func:预处理函数用于从用户LLM请求参数列表中获取与用户问题相关的信息,转换为字符串并返回。 返回的值是后续步骤中嵌入模型的输入。 不同的LLM的请求参数是不同的,因此需要一定程度的预处理。 预处理功能的一些选项包括使用最后的消息内容、没有提示模板的最后内容、连接消息内容、使用摘要压缩上下文等。图像和音频的预处理涉及获取文件名和读取数据。
from gptcache.processor.pre import last_content
content = last_content({"messages": [{"content": "foo1"}, {"content": "foo2"}]})
# content = "foo2"from langchain import PromptTemplate
from gptcache import Config
from gptcache.processor.pre import last_content_without_template
template_obj = PromptTemplate.from_template("tell me a joke about {subject}")
prompt = template_obj.format(subject="animal")
value = last_content_without_template(
data={"messages": [{"content": prompt}]},
cache_config=Config(template=template_obj.template),
)
print(value)
# ['animal']
- 嵌入:根据输入类型将输入转换为多维数字数组。 支持文本、音频和图像嵌入。 Onnx、openai 嵌入模型、SBERT、Cohere、Huggingface 模型(如 Rwkv、Distilbert-base-uncased)是支持的一些文本嵌入。 支持 Timm、ViT 图像嵌入。
from gptcache.embedding import LangChain
from langchain.embeddings.openai import OpenAIEmbeddings
test_sentence="Hello, world."
embeddings = OpenAIEmbeddings(model="your-embeddings-deployment-name")
encoder = LangChain(embeddings=embeddings)
embed = encoder.to_embeddings(test_sentence)- 数据管理器: 负责控制缓存存储和向量存储的操作以及管理内存的驱逐策略。
- 缓存存储:缓存存储用于存储来自 LLM 的响应。 检索缓存的响应以帮助评估相似性,如果存在良好的语义匹配,则将其返回给请求者。
- 向量存储:向量存储模块帮助从输入请求的提取嵌入中找到 K 个最相似的请求。
- 对象存储:如果是多模式缓存,则可以选择需要对象存储。
- 相似度评价: 该模块从缓存存储和矢量存储收集数据,并使用各种策略来确定输入请求和来自矢量存储的请求之间的相似性。 根据这种相似性,它确定请求是否与缓存匹配。 GPTCache 提供了一个用于集成各种策略的标准化接口,以及可供使用的实现集合。 相似度评估根据当前用户的llm请求对调出的缓存数据进行评估,得到一个float值。 CohereRerankEvaluation、SearchDistanceEvaluation、OnnxModelEvaluation、SequenceMatchEvaluation 是一些可用的相似性选项。
- 后处理函数: 用于根据所有满足相似度阈值的缓存数据得到用户问题的最终答案。 目前现有的后处理功能包括
- 首先,获取最相似的缓存答案
- random,随机获取相似的缓存答案
- temp_softmax,根据softmax策略进行选择,可以保证得到的缓存答案具有一定的随机性
自定义用法:
下面的示例使用 sqlite 作为标量存储持久性,使用 faiss 作为向量存储,并使用提及的相似性阈值的 Onnx 模型嵌入。
import time
from gptcache import Cache, Config
from gptcache.adapter import openai
from gptcache.adapter.api import init_similar_cache
from gptcache.embedding import Onnx
from gptcache.manager import manager_factory
from gptcache.processor.post import random_one
from gptcache.processor.pre import last_content
from gptcache.similarity_evaluation import OnnxModelEvaluation
openai_complete_cache = Cache()
encoder = Onnx()
sqlite_faiss_data_manager = manager_factory(
"sqlite,faiss",
data_dir="openai_complete_cache",
scalar_params={
"sql_url": "sqlite:///./openai_complete_cache.db",
"table_name": "openai_chat",
},
vector_params={
"dimension": encoder.dimension,
"index_file_path": "./openai_chat_faiss.index",
},
)
onnx_evaluation = OnnxModelEvaluation()
cache_config = Config(similarity_threshold=0.75)
init_similar_cache(
cache_obj=openai_complete_cache,
pre_func=last_content,
embedding=encoder,
data_manager=sqlite_faiss_data_manager,
evaluation=onnx_evaluation,
post_func=random_one,
config=cache_config,
)
questions = [
"what's github",
"can you explain what GitHub is",
"can you tell me more about GitHub",
"what is the purpose of GitHub",
]
for question in questions:
start_time = time.time()
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": question}],
cache_obj=openai_complete_cache,
)
print(f"Question: {question}")
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response["choices"][0]["message"]["content"]}n')Cache loading.....
Question: what's github
Time consuming: 3.16s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It allows developers to store, manage, and share their code with others. GitHub provides features such as bug tracking, feature management, task management, and wikis for documentation. It also offers a social networking element, allowing users to follow and contribute to projects, collaborate with others, and discover new code repositories.
Question: can you explain what GitHub is
Time consuming: 0.46s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It allows developers to store, manage, and share their code with others. GitHub provides features such as bug tracking, feature management, task management, and wikis for documentation. It also offers a social networking element, allowing users to follow and contribute to projects, collaborate with others, and discover new code repositories.
Question: can you tell me more about GitHub
Time consuming: 0.55s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It allows developers to store, manage, and share their code with others. GitHub provides features such as bug tracking, feature management, task management, and wikis for documentation. It also offers a social networking element, allowing users to follow and contribute to projects, collaborate with others, and discover new code repositories.
Question: what is the purpose of GitHub
Time consuming: 0.56s
Answer: GitHub is a web-based platform used for version control and collaboration in software development projects. It allows developers to store, manage, and share their code with others. GitHub provides features such as bug tracking, feature management, task management, and wikis for documentation. It also offers a social networking element, allowing users to follow and contribute to projects, collaborate with others, and discover new code repositories.
请注意 保持较低的阈值将导致命中缓存的可能性降低。
值越小,与缓存中内容的一致性越高,缓存命中率越低,缓存未命中率越低; 值越大意味着容忍度越高,缓存命中率越高,同时缓存未命中率也越高。
2. 朗链
Langchain 支持缓存,并通过内存缓存、与 GPTcache 集成或通过其他后端和矢量存储(如 Cassandra、Redis、Azure Cosmos DB 等)提供选项。
使用 Langchain 和 Azure CosmosDB 实现缓存:
#from langchain.cache import AzureCosmosDBSemanticCache
from langchain_community.cache import AzureCosmosDBSemanticCache
from langchain_community.vectorstores.azure_cosmos_db import (
CosmosDBSimilarityType,
CosmosDBVectorSearchType,
)
from langchain_openai import OpenAIEmbeddings
import urllib
# Read more about Azure CosmosDB Mongo vCore vector search here
INDEX_NAME = "langchain-test-index"
NAMESPACE = "langchain_test_db.langchain_test_collection"
CONNECTION_STRING = (
"mongodb+srv://cosmoscachedemo:" + urllib.parse.quote_plus("cadccs@24") + "@cosmos4mongo.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000")
DB_NAME, COLLECTION_NAME = NAMESPACE.split(".")
# Default value for these params
num_lists = 3
dimensions = 1536
similarity_algorithm = CosmosDBSimilarityType.COS
kind = CosmosDBVectorSearchType.VECTOR_IVF
m = 16
ef_construction = 64
ef_search = 40
score_threshold = 0.1
set_llm_cache(
AzureCosmosDBSemanticCache(
cosmosdb_connection_string=CONNECTION_STRING,
cosmosdb_client=None,
embedding=AzureOpenAIEmbeddings(),
database_name=DB_NAME,
collection_name=COLLECTION_NAME,
num_lists=num_lists,
similarity=similarity_algorithm,
kind=kind,
dimensions=dimensions,
m=m,
ef_construction=ef_construction,
ef_search=ef_search,
score_threshold=score_threshold,
)
)
3.自动生成器:
AutoGen 是一个完全可定制的开源框架,通过启用多个可以相互交互的代理来帮助编排复杂的工作流程。 AutoGen 支持缓存 API 请求,以便在发出相同请求时可以重复使用它们。
from autogen import Cache
# Use Redis as cache
with Cache.redis(redis_url="redis://localhost:6379/0") as cache:
user.initiate_chat(assistant, message=coding_task, cache=cache)
# Use DiskCache as cache
with Cache.disk() as cache:
user.initiate_chat(assistant, message=coding_task, cache=cache)
# The cache can also be passed directly to the model client's create call
client = OpenAIWrapper(...)
with Cache.disk() as cache:
client.create(..., cache=cache)为了向后兼容,DiskCache 默认处于打开状态,cache_seed 设置为 41。要完全禁用缓存,请在代理的 llm_config 中将 cache_seed 设置为 None。
assistant = AssistantAgent(
"coding_agent",
llm_config={
"cache_seed": None,
"config_list": OAI_CONFIG_LIST,
"max_tokens": 1024,
},
)缓存场景:
聊天:
对于对话式人工智能应用程序,会考虑之前的回合来理解当前回合的上下文并生成答案。 在这种情况下,仅当前查询可能不足以提供正确的响应。 在这种情况下,可以将来自先前回合的关键字的总结或提取添加到当前查询中以用于嵌入生成、缓存响应生成和检索。 GPTCache 支持在输入消息负载中连接多个内容元素,其中可以包括之前的轮次。
文本到图像生成:
除了矢量和缓存存储之外,还定义了对象存储来存储和检索图像。
from gptcache import cache
from gptcache.adapter import openai
from gptcache.processor.pre import get_prompt
from gptcache.embedding import Onnx
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
from gptcache.manager import get_data_manager, CacheBase, VectorBase, ObjectBase
onnx = Onnx()
cache_base = CacheBase('sqlite')
vector_base = VectorBase('milvus', host="localhost", port="19530", dimension=onnx.dimension)
object_base = ObjectBase('local', path="./images")
data_manager = get_data_manager(cache_base, vector_base, object_base)
cache.init(
pre_embedding_func=get_prompt,
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
cache.set_openai_key()
response = openai.Image.create(
prompt="a white siamese cat",
n=1,
size="256x256"
)
image_url = response['data'][0]['url']
response = openai.Image.create(
prompt="a white siamese cat",
n=1,
size="256x256"
)
image_url = response['data'][0]['url']NL2SQL/Codex 场景:
我们可以缓存生成的查询/代码以用于代码生成场景。 可以根据最新数据执行代码。
import time
def response_text(openai_resp):
return openai_resp["choices"][0]["text"]
from gptcache import cache
from gptcache.adapter import openai
from gptcache.embedding import Onnx
from gptcache.processor.pre import get_prompt
from gptcache.manager import CacheBase, VectorBase, get_data_manager
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
print("Cache loading.....")
onnx = Onnx()
data_manager = get_data_manager(CacheBase("sqlite"), VectorBase("faiss", dimension=onnx.dimension))
cache.init(pre_embedding_func=get_prompt,
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
cache.set_openai_key()
questions = [
"A query to list the names of the departments which employed more than 10 employees in the last 3 monthsnSELECT",
"Query the names of the departments which employed more than 10 employees in the last 3 monthsnSELECT",
"List the names of the departments which employed more than 10 employees in the last 3 monthsnSELECT",
]
for question in questions:
start_time = time.time()
response = openai.Completion.create(
engine="gpt-35-turbo-instruct",
prompt="### Postgres SQL tables, with their properties:n#n# Employee(id, name, department_id)n# Department(id, name, address)n# Salary_Payments(id, employee_id, amount, date)n#n### " + question,
temperature=0,
max_tokens=150,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
stop=["#", ";"]
)
print(question, response_text(response))
print("Time consuming: {:.2f}s".format(time.time() - start_time))回复:
SELECT Department.name
FROM Department
INNER JOIN Employee ON Employee.department_id = Department.id
INNER JOIN Salary_Payments ON Salary_Payments.employee_id = Employee.id
WHERE Salary_Payments.date >= CURRENT_DATE - INTERVAL '3 months'
GROUP BY Department.name
HAVING COUNT(Employee.id) > 10
Time consuming: 0.71s
应用语义缓存时的关键考虑因素:
- 频繁问题和答案模式的识别会随着时间的推移而演变,并且可能涉及来自用户/主题专家的反馈循环。 在初始生产部署期间,缓存机会有限。 随着应用程序获得更多关注,将会有足够的客户反馈响应可用于缓存层。
- 对个性化问题的响应(可能基于用户的角色或与用户相关的特定问题,其中答案对于用户而言是可变的,或者可能涉及获取用户特定信息的查询的时间安排)需要谨慎处理。 例如。 人力资源机器人可以回答用户的休假余额查询。 这可能涉及根据员工级别/职务或根据个人的具体休假余额做出不同的反应。
- 不正确的缓存管理/设计可能会导致数据和提示泄漏。 例如。 如上所述缓存个性化响应可能会导致这些本可避免的情况。
- 需要仔细考虑用于相似性的阈值。 阈值太低可能意味着准确性和用户体验问题,而阈值太高则意味着缓存响应的使用非常有限。
- 温度设置通常用于生成对同一查询的不同响应。 为默认/零温度设置和调用 LLM 生成响应的更高温度实施缓存。
- 对于基于 RAG 的用例,文档可能会在索引/搜索层中更新。 在这种情况下,缓存将变得过时,因此需要缓存新响应以避免给出错误/过时的响应。
参考:
1713155751
#使用语义缓存优化 #Azure #OpenAI #应用程序
2024-04-10 06:01:09










