

Mattermost 在大型部署中使用 Elasticsearch 来减少数据库在运行搜索查询时承受的压力,同时返回更好的、经过微调的结果。为了实现这一点,Elasticsearch 需要索引我们要搜索的所有数据,以便在请求时可以快速检索数据。一旦数据被索引,一切都会按预期运行,我们的用户会很高兴,我们的开发人员也会很高兴,生活会很美好。
但是,我最近测试了很久没尝试过的事情:从头开始索引一个相当大的数据库(包含 1 亿条帖子)。当数据库已经建立索引后,后续对新帖子和文件的索引速度会非常快,因此 Elasticsearch 的正常使用是没有问题的,但从头开始索引速度很慢:
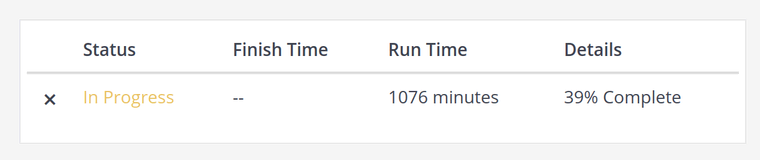
这张截图是我们的作业系统,它告诉我们 Elasticsearch 索引作业已经运行了大约 18 个小时,但还未完成一半的任务 🙁 并且进度不是线性的,越往后进度越慢!这里显然出了问题。
让我们先来调查一下这里到底是什么地方速度慢,因为有很多活动部件:可能是数据库、Mattermost 服务器、Elasticsearch 服务器、网络或资源不足的机器。
看看我们的 Mattermost 性能监控 Grafana 仪表板 当索引作业正在运行时,问题一目了然:
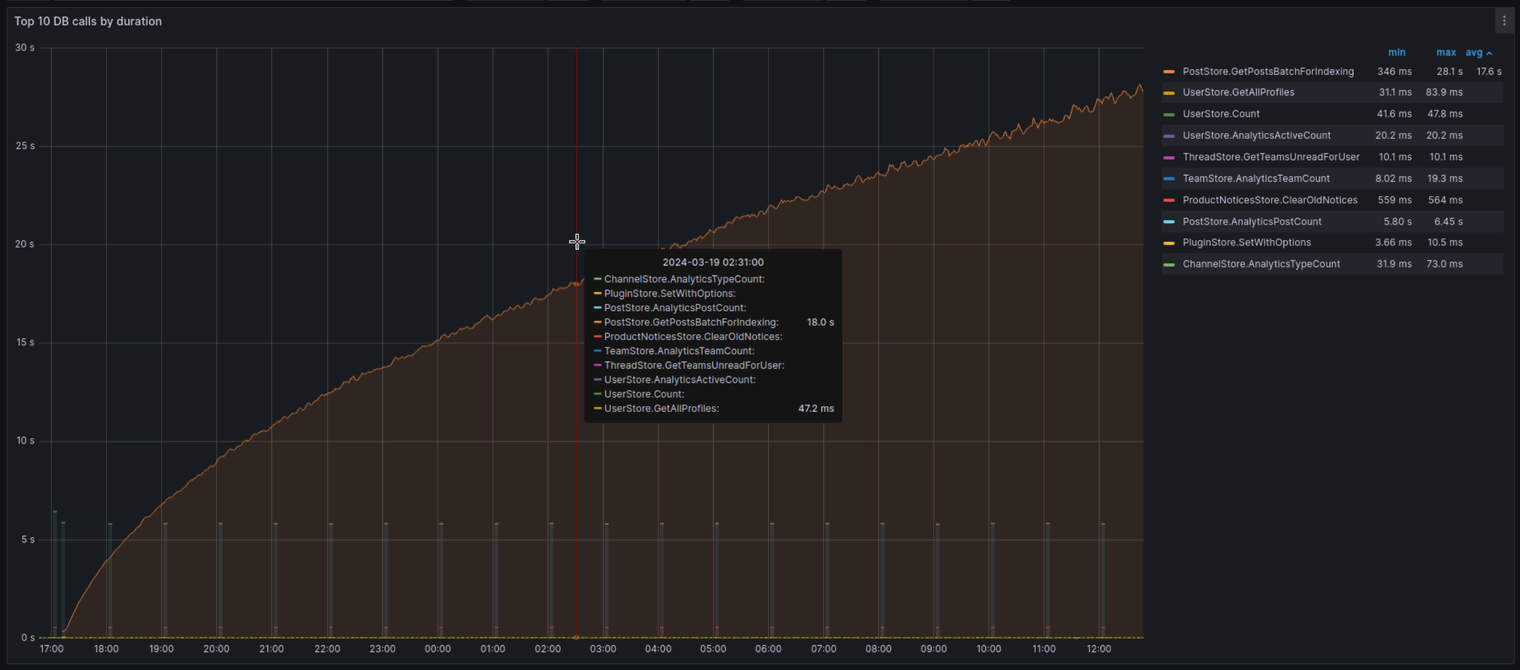
上图按持续时间显示了前 10 个数据库调用,这些调用可归结为(稍微简化)以下 Prometheus 查询:
topk(10,
sum(increase(mattermost_db_store_time_sum[5m])) by (method)
/
sum(increase(mattermost_db_store_time_count[5m])) by (method)
)我们测量每个数据库方法完成所需的时间,取过去 5 分钟的平均值,并按秒绘制图表,仅显示前 10 种方法。
从图表上看,有一个明显的异常值: PostStore.GetPostsBatchForIndexing随着索引作业的进行,它花费的时间越来越多,最终达到 30 秒,然后超时。 查看代码,我们看到了导致所有这些问题的确切查询:
SELECT Posts.*, Channels.TeamId
FROM Posts LEFT JOIN Channels ON Posts.ChannelId = Channels.Id
WHERE
Posts.CreateAt > ?1
OR
(Posts.CreateAt = ?1 AND Posts.Id > ?2)
ORDER BY Posts.CreateAt ASC, Posts.Id ASC
LIMIT ?3;此查询的作用很简单:它按创建时间戳对所有帖子进行排序,并返回前 N 个(由调用者提供的限制)比提供的时间戳更新的帖子。查询需要检查帖子的 ID,并涵盖两个帖子同时发生的罕见情况。它还与 Channels 表连接,但仅返回帖子的 TeamId 及其其他数据。
然后,索引作业将在此查询的基础上构建,并反复运行,直到所有帖子都被索引。在伪代码中,它看起来像这样:
func IndexingJob() {
t := 0
id := ""
limit := 1000
for {
// Run the query
batch := GetPostsBatchForIndexing(t, id, limit)
// Index the posts returned by the query
elasticsearchService.Index(batch)
// Stop when we get less than `limit` posts
if len(batch) < limit {
break
}
// Update the timestamp and id to newest post's
newestPost := batch[len(batch)-1]
t = newestPost.CreateAt
id = newestPost.Id
}
}第一次调查
现在我们了解了我们正在处理的问题以及整个系统的哪个部分出现了问题,我们就可以开始真正的调查了。
尝试优化 SQL 查询永远不会遵循预定义的计划,但可以应用一些方法来帮助更快、更一致地找到问题并可能找到解决方案。不过,我并没有做任何这些,而且我的调查一开始是混乱的和本能驱动的。永远不要在家里这样做。
我对此查询的第一个担忧是:为什么每次执行它所花的时间越来越长?答案其实很简单,但我一开始并不知道。所以我首先查看的是手头已有的数据:查询的 AWS 性能洞察:
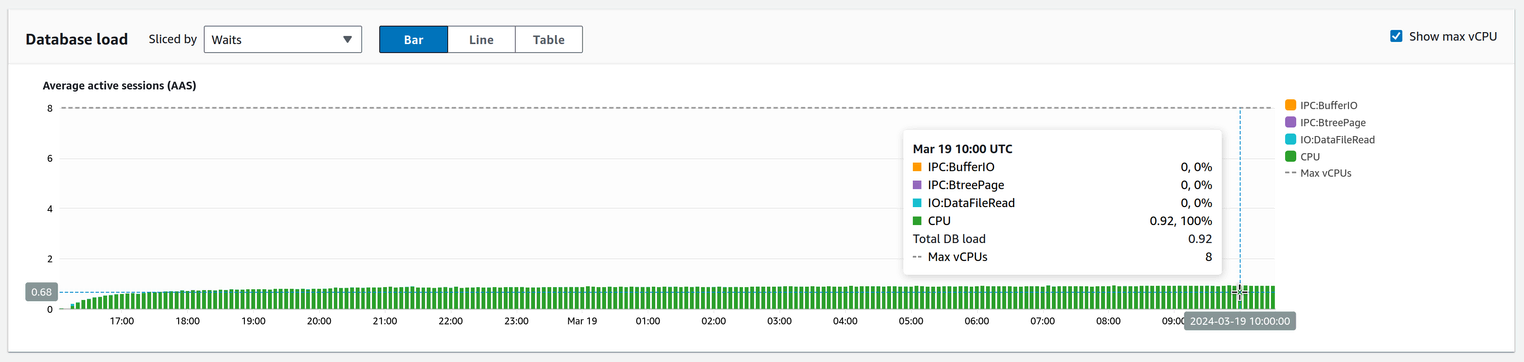
这给了我第一个线索:查询几乎 100% 的运行时间都花在了 CPU 上。这意味着查询的瓶颈不是读取或写入数据所需的时间,而是 过程 那些数据。很有趣。
然后我开始玩查询。我做的第一件事当然是运行 EXPLAIN ANALYZE。最近,我养成了添加 BUFFERS 此选项,因此 EXPLAIN 提供了更多数据。 一篇精彩的博客文章 在 BUFFERS 选项,所以我不会在这里详细介绍,但是通过复制 pgMustard 的定义,简短而切中要点,我们可以理解它的作用:
BUFFERS 通过添加值来扩展 EXPLAIN,以描述每个操作读取/写入的数据。
我们不仅获得了查询计划的信息,还获得了我们移动的实际数据的信息。太棒了。
现在,选择查询接收的参数的一些数据(时间戳、帖子 ID 和限制),我运行 EXPLAIN (ANALYZE, BUFFERS) 并得到以下结果:
mmdb=> EXPLAIN (ANALYZE, BUFFERS) SELECT Posts.*, Channels.TeamId FROM Posts LEFT JOIN Channels ON Posts.ChannelId = Channels.Id WHERE Posts.CreateAt > '1687424888405' OR (Posts.CreateAt="1687424888405" AND Posts.Id > 'tpomh9yu1tffmdp6dopobwuc9h') ORDER BY Posts.CreateAt ASC, Posts.Id ASC LIMIT 10000;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1.22..2287.94 rows=10000 width=464) (actual time=23921.236..23954.229 rows=10000 loops=1)
Buffers: shared hit=40557115
-> Incremental Sort (cost=1.22..13998881.93 rows=61217938 width=464) (actual time=23921.235..23953.205 rows=10000 loops=1)
Sort Key: posts.createat, posts.id
Presorted Key: posts.createat
Full-sort Groups: 311 Sort Method: quicksort Average Memory: 45kB Peak Memory: 45kB
Buffers: shared hit=40557115
-> Nested Loop Left Join (cost=1.00..11421751.31 rows=61217938 width=464) (actual time=23920.970..23947.067 rows=10001 loops=1)
Buffers: shared hit=40557115
-> Index Scan using idx_posts_create_at on posts (cost=0.57..9889434.54 rows=61217938 width=461) (actual time=23920.930..23931.063 rows=10001 loops=1)
Filter: ((createat > '1687424888405'::bigint) OR ((createat="1687424888405"::bigint) AND ((id)::text > 'tpomh9yu1tffmdp6dopobwuc9h'::text)))
Rows Removed by Filter: 40920000
Buffers: shared hit=40553119
-> Memoize (cost=0.43..0.70 rows=1 width=30) (actual time=0.001..0.001 rows=1 loops=10001)
Cache Key: posts.channelid
Cache Mode: logical
Hits: 9002 Misses: 999 Evictions: 0 Overflows: 0 Memory Usage: 151kB
Buffers: shared hit=3996
-> Index Scan using channels_pkey on channels (cost=0.42..0.69 rows=1 width=30) (actual time=0.007..0.007 rows=1 loops=999)
Index Cond: ((id)::text = (posts.channelid)::text)
Buffers: shared hit=3996
Planning:
Buffers: shared hit=112
Planning Time: 0.501 ms
Execution Time: 23954.974 ms
(25 rows)这……需要消化的东西太多了。以下是一些要点:
- 倒数第二行,执行时间,显示此查询大约需要 24 秒才能完成。这就是我们想要修复的问题。
- 查询计划显示节点。从内到外:
- 首先,几个索引扫描节点:
- 一个在 Posts 表上,使用应用 WHERE 条件的过滤器,使用覆盖 CreateAt 字段的索引。但是,为什么不使用此表上的另一个索引(CreateAt、Id)呢?我们还不知道。
- 另一个是在 Channels 表上,使用 Index Cond 应用连接条件(帖子的 ID 等于频道的 ID),使用主键(即 ID)上的索引。
- 然后,它在 Posts 和 Channels 表之间执行 JOIN 操作。
- 最后,它进行增量排序,使用 Posts.CreateAt 和 Posts.Id 作为排序键,注意我们有一个已经排序的键 Posts.CreateAt,因为我们之前使用了 idx_posts_create_at 索引。
- 首先,几个索引扫描节点:
- 共享命中缓冲区的数量为 四千万 在 Posts 表的 Index Scan 节点上以及包装的 Nested Loop Left Join 节点上。这可不少。
这里的第 3 点很重要。虽然嵌套循环中的命中次数 它的细微差别,这给了我们另一个线索:这就是 CPU 被占用的地方。即使这并不意味着我们从缓存中读取了 4000 万个块(我们需要一个相当大的缓存来实现这一点),也意味着我们 加工 4000 万个区块。我们可以看看这实际上意味着多少数据:
mmdb=> SELECT pg_size_pretty(40557115 * current_setting('block_size')::bigint);
pg_size_pretty
----------------
309 GB
(1 row)因此查询正在处理 三百千兆字节。 不错。
第一个解决方案
我尝试解决这个问题的第一件事就是删除 JOIN 与 Channels 表。这两个表都很大,所以我担心这会给查询增加很多开销。但事实并非如此。没有这个查询所花费的时间 JOIN 几乎和它一样。
那么接下来呢?下一步主要是运气。我想继续理解查询,所以我不断简化它。如果 JOIN 不是问题,那么唯一的其他复杂性就在于 WHERE 健康)状况: CreateAt > t OR (CreateAt = t AND Id > id)。
所以我跑了 EXPLAIN 查询跳过了 OR; 那是:
SELECT Posts.*, Channels.TeamId
FROM Posts LEFT JOIN Channels ON Posts.ChannelId = Channels.Id
WHERE Posts.CreateAt > ?1 -- <- only the first condition here
ORDER BY Posts.CreateAt ASC, Posts.Id ASC
LIMIT ?3;我得到了一个非常有趣的结果:
mmdb=> EXPLAIN (ANALYZE, BUFFERS) SELECT Posts.*, Channels.TeamId FROM Posts LEFT JOIN Channels ON Posts.ChannelId = Channels.Id WHERE Posts.CreateAt > '1687424888405' ORDER BY Posts.CreateAt ASC, Posts.Id ASC LIMIT 10000;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1.14..1616.83 rows=10000 width=464) (actual time=0.347..33.077 rows=10000 loops=1)
Buffers: shared hit=13949
-> Incremental Sort (cost=1.14..9890887.64 rows=61217938 width=464) (actual time=0.346..32.054 rows=10000 loops=1)
Sort Key: posts.createat, posts.id
Presorted Key: posts.createat
Full-sort Groups: 311 Sort Method: quicksort Average Memory: 45kB Peak Memory: 45kB
Buffers: shared hit=13949
-> Nested Loop Left Join (cost=1.00..7313757.02 rows=61217938 width=464) (actual time=0.053..25.892 rows=10001 loops=1)
Buffers: shared hit=13949
-> Index Scan using idx_posts_create_at on posts (cost=0.57..5781440.25 rows=61217938 width=461) (actual time=0.032..9.802 rows=10001 loops=1)
Index Cond: (createat > '1687424888405'::bigint)
Buffers: shared hit=9953
-> Memoize (cost=0.43..0.70 rows=1 width=30) (actual time=0.001..0.001 rows=1 loops=10001)
Cache Key: posts.channelid
Cache Mode: logical
Hits: 9002 Misses: 999 Evictions: 0 Overflows: 0 Memory Usage: 151kB
Buffers: shared hit=3996
-> Index Scan using channels_pkey on channels (cost=0.42..0.69 rows=1 width=30) (actual time=0.007..0.007 rows=1 loops=999)
Index Cond: ((id)::text = (posts.channelid)::text)
Buffers: shared hit=3996
Planning:
Buffers: shared hit=112
Planning Time: 0.440 ms
Execution Time: 33.735 ms
(24 rows)看到执行时间了吗?是 30 国家的秒,或者说比原始查询少了约 1000 倍!共享命中缓冲区为 13949,或者说更合理的 109 MiB。在我继续查看这个计划之前,我立即尝试运行仅包含第二部分的查询 OR 条件;即:
SELECT Posts.*, Channels.TeamId
FROM Posts LEFT JOIN Channels ON Posts.ChannelId = Channels.Id
WHERE Posts.CreateAt = ?1 AND Posts.Id > ?2 -- <- only the second condition here
ORDER BY Posts.CreateAt ASC, Posts.Id ASC
LIMIT ?3;我没有想太多,老实说,我预计这会再次花费大约 24 秒,这样我就可以专注于优化这一部分。但我得到的结果是:
agnivaltdb=> EXPLAIN (ANALYZE, BUFFERS) SELECT Posts.*, Channels.TeamId FROM Posts LEFT JOIN Channels ON Posts.ChannelId = Channels.Id WHERE Posts.CreateAt="1687424888405" AND Posts.Id > 'tpomh9yu1tffmdp6dopobwuc9h' ORDER BY Posts.CreateAt ASC, Posts.Id ASC LIMIT 10000;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.99..17.03 rows=1 width=464) (actual time=0.015..0.015 rows=0 loops=1)
Buffers: shared hit=4
-> Nested Loop Left Join (cost=0.99..17.03 rows=1 width=464) (actual time=0.014..0.014 rows=0 loops=1)
Buffers: shared hit=4
-> Index Scan using idx_posts_create_at_id on posts (cost=0.57..8.59 rows=1 width=461) (actual time=0.013..0.013 rows=0 loops=1)
Index Cond: ((createat="1687424888405"::bigint) AND ((id)::text > 'tpomh9yu1tffmdp6dopobwuc9h'::text))
Buffers: shared hit=4
-> Index Scan using channels_pkey on channels (cost=0.42..8.44 rows=1 width=30) (never executed)
Index Cond: ((id)::text = (posts.channelid)::text)
Planning:
Buffers: shared hit=112
Planning Time: 0.437 ms
Execution Time: 0.047 ms
(13 rows)它花费了 0.047 毫秒!这……嗯,比原始查询快了约 500000(五十万)倍。什么???
啊,等等,它没有返回任何行,这很有道理。它没有返回任何行,因为它涵盖了一种非常罕见的情况,因为我们正在寻找与另一篇文章在同一毫秒内发生的文章,并且其 ID 大于给定的 ID。这并非不可能,但也不常见。
但重要的问题是:我原来的 24 秒去哪儿了?为什么这两个单独的查询要花费 30 国家的总共 200 秒而不是 30 秒?
我仍有太多问题而答案不够,但我做出了一个决定:我将把原始查询拆分成这两个,一个接一个地运行它们,然后在 Mattermost 服务器代码中收集结果。这会使代码变得有点复杂,但这是值得的。我对自己说,明天早上我会这样做。
真正理解一切
当然,第二天早上我也没有这样做,而是回头去了解发生了什么。为什么我们在原始查询中得到了这么多共享命中缓冲区?为什么每次执行它都要花更长的时间?为什么拆分查询返回的答案完全相同,但速度却快了 1000 倍?
好吧,我已经拥有了理解一切所需的所有数据;只是我没有给予应有的关注。
回顾原始查询的查询计划和仅通过以下方式过滤的查询计划 CreateAt > ...,我们看到了一个非常重要的区别。让我们仔细看看 Index Scan 两种情况下的节点。
首先,原始查询:
-> Index Scan using idx_posts_create_at on posts (cost=0.57..9889434.54 rows=61217938 width=461) (actual time=23920.930..23931.063 rows=10001 loops=1)
Filter: ((createat > '1687424888405'::bigint) OR ((createat="1687424888405"::bigint) AND ((id)::text > 'tpomh9yu1tffmdp6dopobwuc9h'::text)))
Rows Removed by Filter: 40920000
Buffers: shared hit=40553119现在,只通过 CreateAt > ...:
-> Index Scan using idx_posts_create_at on posts (cost=0.57..5781440.25 rows=61217938 width=461) (actual time=0.032..9.802 rows=10001 loops=1)
Index Cond: (createat > '1687424888405'::bigint)
Buffers: shared hit=9953你发现区别了吗?第一个使用 Filter,在此过程中删除了 4000 万行,而第二个使用 Index Cond,只检查索引本身。
这就是主要的区别。回到简短而切中要点的描述 芥末:
Index Cond 是用于从索引中查找行的位置的条件。Postgres 使用索引的结构化特性快速跳转到它要查找的行。
尽管目的与“筛选”,实现方式则完全不同。 在“过滤器”中,将根据行的值检索行,然后将其丢弃。因此,您可以在同一个操作中找到“索引条件”和“过滤器”。
这就是关键的区别:原始查询正在通过 全部 中的行 Posts 表,然后根据条件丢弃或保留它们,而第二个只查看索引并检索所需的行。 一个问题得到解答!
但这也解释了为什么查询每次执行所需的时间越来越长:因为它按从最旧到最新的顺序排列帖子,并且每个查询都使用最后一批的最新时间戳,所以每次都需要丢弃越来越多的行。为了更清楚地说明这一点,假设我们的 Posts 表有 1000 个帖子,我们每次索引 100 个帖子的批次。然后作业按如下方式运行:
- 第一批将返回 0 到 99 个帖子,不会丢弃任何帖子,因此速度会非常快。正如预期的那样,它总共处理了 100 个帖子。
- 第二批将返回第 100 到第 199 条帖子,但必须先丢弃前 100 条帖子。不过,前 100 条帖子已被阅读,因此总共处理了 200 条帖子。
- 第三批将返回第 200 到第 299 个帖子,丢弃前 200 个帖子。总共处理了 300 个帖子。
- ...
- ...
- ...
- 第十批(也是最后一批)将返回帖子 900 到 999,丢弃前 900 个帖子。最后一批处理了 1000 个帖子,即 所有的 桌子。
我的另外两个问题也得到了回答:原始查询有太多的共享命中缓冲区,并且花费的时间越来越长,仅仅是因为它最终要经过 一亿 数据库中的帖子。查询不佳。
美丽的解决方案
尽管我们现在确实了解了一切,但我们仍然需要完成原来的任务:将原始查询分成两个,独立运行它们,然后在服务器中收集结果。
但还有另一种选择!现在我明白了一切,我能够用召唤 StackOverflow 之神所需的确切咒语来寻找类似的案例。他们 发表。谢谢 StackOverflow。也谢谢 你, 劳伦兹·阿尔伯。
PostgreSQL 中有一个很方便的功能,叫做 行构造函数比较 允许我比较列的元组。这正是我们所需要的。而不是这样做 CreateAt > ?1 OR (CreateAt = ?1 AND Id > ?2), 我们可以做的 (CreateAt, Id) > (?1, ?2)。并且行构造函数比较是按字典顺序排列的,这意味着它在语义上与我们之前的相同!
因此我们只需要将原始查询转换为以下内容:
SELECT Posts.*, Channels.TeamId
FROM Posts LEFT JOIN Channels ON Posts.ChannelId = Channels.Id
WHERE (Posts.CreateAt, Posts.Id) > (?1, ?2) -- <- lexicographical comparisons to the rescue!
ORDER BY Posts.CreateAt ASC, Posts.Id ASC
LIMIT ?3;结果如何?让我们看看:
mmdb=> EXPLAIN (ANALYZE, BUFFERS) SELECT Posts.*, Channels.TeamId FROM Posts LEFT JOIN Channels ON Posts.ChannelId = Channels.Id WHERE (Posts.CreateAt, Posts.Id) > ('1687424888405', 'tpomh9yu1tffmdp6dopobwuc9h') ORDER BY Posts.CreateAt ASC, Posts.Id ASC LIMIT 10000;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1.15..1666.83 rows=10000 width=464) (actual time=0.366..34.053 rows=10000 loops=1)
Buffers: shared hit=13951
-> Incremental Sort (cost=1.15..10196977.36 rows=61217938 width=464) (actual time=0.365..33.031 rows=10000 loops=1)
Sort Key: posts.createat, posts.id
Presorted Key: posts.createat
Full-sort Groups: 311 Sort Method: quicksort Average Memory: 45kB Peak Memory: 45kB
Buffers: shared hit=13951
-> Nested Loop Left Join (cost=1.00..7619846.74 rows=61217938 width=464) (actual time=0.059..26.840 rows=10001 loops=1)
Buffers: shared hit=13951
-> Index Scan using idx_posts_create_at on posts (cost=0.57..6087529.97 rows=61217938 width=461) (actual time=0.040..10.548 rows=10001 loops=1)
Index Cond: (createat >= '1687424888405'::bigint)
Filter: (ROW(createat, (id)::text) > ROW('1687424888405'::bigint, 'tpomh9yu1tffmdp6dopobwuc9h'::text))
Rows Removed by Filter: 2
Buffers: shared hit=9955
-> Memoize (cost=0.43..0.70 rows=1 width=30) (actual time=0.001..0.001 rows=1 loops=10001)
Cache Key: posts.channelid
Cache Mode: logical
Hits: 9002 Misses: 999 Evictions: 0 Overflows: 0 Memory Usage: 151kB
Buffers: shared hit=3996
-> Index Scan using channels_pkey on channels (cost=0.42..0.69 rows=1 width=30) (actual time=0.007..0.007 rows=1 loops=999)
Index Cond: ((id)::text = (posts.channelid)::text)
Buffers: shared hit=3996
Planning:
Buffers: shared hit=112
Planning Time: 0.471 ms
Execution Time: 34.716 ms
(26 rows)34 毫秒,太棒了!查询速度提高了 1000 倍,而且比原始查询更具可读性,堪称教科书级的双赢。
如果你看一下 Index Scan 节点,你会注意到 PostgreSQL 现在正在使用 Index Cond,因此检查索引以找到这些帖子,然后才应用过滤器。共享命中缓冲区下降到 9955,只有 78 MiB。是不是很漂亮?
(为什么查询计划器不会自动转换这样的条件 x > a OR (x == a AND y > b) 到 (x, y) > (a, b) 直到今天我还是不明白这一点。)
我们需要的解决方案
就这样我完成了。但后来我想起我们不仅支持 PostgreSQL,还支持 MySQL。这让我不寒而栗。
当然,MySQL 中的行为完全相反:
让我们运行一个 EXPLAIN ANALYZE (不 BUFFERS 在 MySQL 中,抱歉)在 MySQL 中运行的查询。首先,原始的:
mysql> EXPLAIN ANALYZE SELECT Posts.*, Channels.TeamId FROM Posts USE INDEX(idx_posts_create_at_id) LEFT JOIN Channels ON Posts.ChannelId = Channels.Id WHERE Posts.CreateAt > 1557752415221 OR (Posts.CreateAt = 1557752415221 AND Posts.Id > 'ad59ire57tfwmjr5r8xqxc75qw') ORDER BY Posts.CreateAt ASC, Posts.Id ASC LIMIT 10000;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit: 10000 row(s) (cost=7472068.91 rows=10000) (actual time=0.063..164.174 rows=10000 loops=1)
-> Nested loop left join (cost=7472068.91 rows=5559093) (actual time=0.062..163.450 rows=10000 loops=1)
-> Index range scan on Posts using idx_posts_create_at_id over (CreateAt = 1557752415221 AND 'ad59ire57tfwmjr5r8xqxc75qw' < Id) OR (1557752415221 < CreateAt), with index condition: ((Posts.CreateAt > 1557752415221) or ((Posts.CreateAt = 1557752415221) and (Posts.Id > 'ad59ire57tfwmjr5r8xqxc75qw'))) (cost=1357066.29 rows=5559093) (actual time=0.043..97.358 rows=10000 loops=1)
-> Single-row index lookup on Channels using PRIMARY (Id=Posts.ChannelId) (cost=1.00 rows=1) (actual time=0.006..0.006 rows=1 loops=10000)
|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.18 sec)0.18 秒。这……确实不错。那新款呢?
mysql> EXPLAIN ANALYZE SELECT Posts.*, Channels.TeamId FROM Posts USE INDEX(idx_posts_create_at_id) LEFT JOIN Channels ON Posts.ChannelId = Channels.Id WHERE (Posts.CreateAt, Posts.Id) > (1557752415221, 'ad
59ire57tfwmjr5r8xqxc75qw') ORDER BY Posts.CreateAt ASC, Posts.Id ASC LIMIT 10000;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit: 10000 row(s) (cost=11119405.48 rows=10000) (actual time=5295.106..5455.285 rows=10000 loops=1)
-> Nested loop left join (cost=11119405.48 rows=10000) (actual time=5295.105..5454.572 rows=10000 loops=1)
-> Filter: ((Posts.CreateAt,Posts.Id) > (1557752415221,'ad59ire57tfwmjr5r8xqxc75qw')) (cost=221.48 rows=10000) (actual time=5295.078..5388.668 rows=10000 loops=1)
-> Index scan on Posts using idx_posts_create_at_id (cost=221.48 rows=10000) (actual time=0.055..5314.753 rows=600000 loops=1)
-> Single-row index lookup on Channels using PRIMARY (Id=Posts.ChannelId) (cost=1.00 rows=1) (actual time=0.006..0.006 rows=1 loops=10000)
|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (5.46 sec)啊,不错,慢了 50 倍。哎呀。
这种结果很难避免:我不得不将代码流分成两部分,使用 PostgreSQL 时使用美观的查询,使用 MySQL 时使用原始查询。这就是 最终合并的变更。有点伤心,但事实就是这样。
我们学到了什么
毕竟,这是一次有趣的旅程,而且绝对是一项很好的优化:谁不喜欢让某件事快一千倍呢?它最终登陆了 v9.7.0 及更高版本,并从 v9.5.3 开始移植到 9.5 ESR。
此外,我还了解到一些非常有趣的事情:
- 总是使用
BUFFERS当运行EXPLAIN。它提供了一些可能对调查至关重要的数据。 - 总是,总是试图得到一个
Index Cond(称为Index range scan在 MySQL 中)而不是Filter。 - 永远、永远、永远假设 PostgreSQL 和 MySQL 的行为会有所不同。因为它们确实如此。










