· 12 分钟
同步服务充当幕后大脑 邮递员收藏。 它是 Postman 最古老的单体之一,作为内部后端服务,由 帆 和 水线 ORM,它为集合的全方位 CRUD 操作提供支持。
去年,我们写过关于 我们如何分解同步服务 并逐渐将功能从它身上移走。 在这篇博文中,我们将讨论 Postman 工程师团队遇到的存储问题以及我们如何解决该问题。
问题
同步服务从 2014 年开始运行,我们开始面临与数据库层物理存储相关的问题。
对于上下文,同步服务运行在 AWS RDS 极光 具有单个主写入器节点和 3-4 个读取器的集群,所有这些节点都是 r6g.8xlarge。 AWS RDS 的物理存储大小限制为 128TiB 对于每个 RDS 集群。 为简单起见,我们将以 TB 为单位表示所有存储数量,其中 1TiB = 1.09951TB。
我们徘徊在约 95TB 左右,我们的摄取率约为每月 2TB。 按照这个速度,我们意识到我们将在接下来的 6-8 个月内看到摄取问题,这可能会导致整个 Postman 用户群出现严重停机。

实验
起初,我们认为这个问题很容易解决。 我们只需从集群中删除旧的、不需要的记录,并逐渐将它们发送到冷存储(即发送到 S3 或辅助数据库集群),这些记录永远不需要被访问。 然后我们只需维护该集群的备份。
最初的方法并没有奏效,因为我们意识到仅仅删除数据并不能释放空间。 经过进一步调查,我们发现修剪记录 sysvar_innodb_file_per_table 配置为 true/ON 不会释放整个集群的空间。 相反,它只释放可由同一个表重复使用的片段。 其他表无法声明该空间用于插入,因此我们的问题没有解决。
如果我们想继续采用修剪记录的方法,那么我们将不得不重建表以释放空间。 该策略将导致大量、不受控制的停机时间,而且我们不知道需要多长时间。 因此,这种方法对我们来说是不行的,因为我们不能将关键业务数据库置于危险之中,只是希望它能成功。
一旦我们确定了这个限制,我们就意识到解决方案可能不是那么简单。 因此,我们决定列出基本期望:
- 不能出现停机,因为关闭数据库将使 Postman 平台无法使用。
- Postman平台可以在
READ ONLY模式持续 10-20 分钟。 - 我们必须在所有方面保持对数据库的完全控制。 这意味着如果在此过程中出现问题,我们应该能够在不到五分钟的时间内恢复数据库和平台。 我们还必须确保不存在数据丢失或数据完整性问题。
- 我们必须确保依赖服务可以容忍子系统(同步)进入
READ ONLY模式。 - Postman Web 平台和桌面应用程序必须保持可用,但性能下降程度较小。
三步走法
为了解决这个问题,我们将其分为三个独立的桶。
步骤 1:删除未使用的表
随着时间的推移,我们积累了大量的备份和未使用的表。 我们必须识别这些表,并确保如果它们不再存在于数据库中,我们的应用程序不会受到影响。
我们通过运行查询来识别表 information_schema 在我们的 RDS MySQL 集群上:
SELECT *
FROM information_schema.tables
WHERE table_schema IN ('DB_NAME') // note this is db name.
AND engine IS NOT NULL
AND ((update_time < (now() - INTERVAL 30 DAY)) OR update_time IS NULL);
此查询帮助我们可靠地找出哪些表在过去 30 天内没有被写入。 我们还通过 NewRelic 和 VividCortex 系统进行了第二轮检查,我们在内部使用这些系统进行监控和可观察性目的。
获得上述数据后,我们进行了手动审核并最终确定了可以安全删除的表列表。 我们还确保应用程序层不会在任何地方引用这些表。
上述过程是在我们的测试版和临时环境中执行的,以进行最终确认。
第 2 步:调整我们的仅追加表策略
我们发现大部分空间被我们的仅附加表占用。 仅追加表是可以创建或插入记录但无法更新记录的表。 根据用例,删除是可选的。
我们确定了 2-3 个表,构成约 35TB 的存储空间。 我们确定的表之一称为“修订”,我们在 我们之前关于此服务的博客文章,还有。
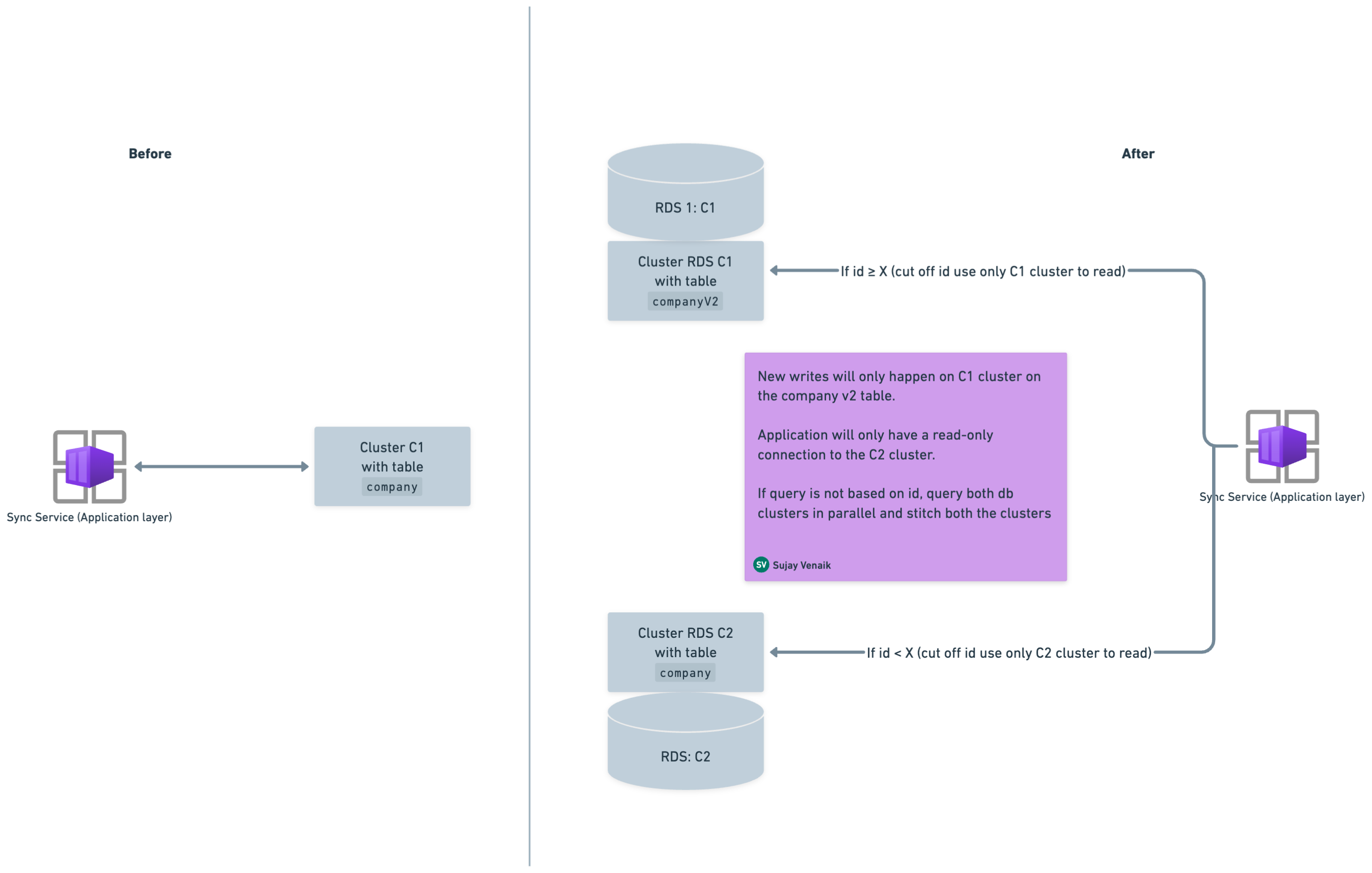
这些表基于自动增量计数器,并且大多数查询模式都基于自动增量计数器。 因此,我们确定了一个截止 ID(假设为 X)并创建了一个策略,其中将从 C1 集群中读取大于或等于 X 的记录,以及较旧的记录(即 ID 小于 X 的记录) )将从 C2 集群中读取。
在进行这些步骤之前,让我们先明确定义这些术语:
- C1:连接到运行 MySQL v5.7 的应用程序的主 RDS 集群。
- C2:从 C1 的快照初始化的 RDS 集群。
这些是涉及的步骤:
- 在C1集群中创建v2版本表。 例如,如果您有一个名为
company,创建另一个具有相同架构的表,名为companyv2。 - 在两个表上开始双重写入(即
company和companyv2)。 双写入有助于避免滚动部署期间出现任何数据一致性问题,因为数据会重叠。 - 从 C1 的快照启动一个新的 C2 集群,其中将包含两个表
company和companyv2直到时间T。 - 当双写入打开时,找到两个表之间的公共截止 ID。 在该 ID 上方,您将读取
companyv2,在该 ID 下方,您将读取company。 - 按如下方式分割读数,其中截止 ID 为 X:
companyV2表将从 C1 读取,其中 ID >= X。company将从 C2 读取表,其中 ID < X。
- 两个都
companyv2:C1和company:C2将根据查询组成完整的结果。 - 应用程序只需要 C2 上的只读连接,因为数据永远不会写入 C2。
这种方法使我们能够从 C1(即主集群)中释放完整的旧数据,这实际上帮助我们释放了更多的整体空间。
步骤 3:可靠地释放大于 2TB 的表空间
这对我们来说是最棘手的部分,因为我们最初的修剪记录实验失败了。
我们尝试简单地删除一个 15TB 大的表。 然而,这需要很长时间,DML操作指标激增,整个数据库进入不可控状态,我们只能等待。 所以,这个实验也是失败的,因为我们无法以无界的方式进行。
我们回到绘图板并列出了我们的基本期望。 我们知道我们不应该对这些期望妥协,我们需要制定一个能够遵守这些期望的策略。 我们的主要期望是,我们不应在 C1(即连接到运行 MySQL v5.7 的应用程序的主 RDS 集群)上执行任何操作。 这种期望确保生产应用程序可以继续无缝运行,不会出现任何影响 Postman 用户的问题。
我们开始挖掘,我们希望使用类似的方法来实现主服务器和副本服务器之间的同步。 重要的是,我们没有将主服务器同步到副本,但我们希望同步两个单独的 RDS 集群,并确保两个集群之间的最大滞后只是副本滞后。
但复制是如何进行的呢? 二进制日志 记录对 MySQL 数据库所做的所有更改,允许您在发生灾难时复制这些更改或恢复数据(阅读有关 MySQL 中主节点和副本节点之间的同步的信息) 这里)。 我们希望使用类似的方法,但我们希望使用它来启用不同 RDS 集群的两个独立主节点之间的复制。
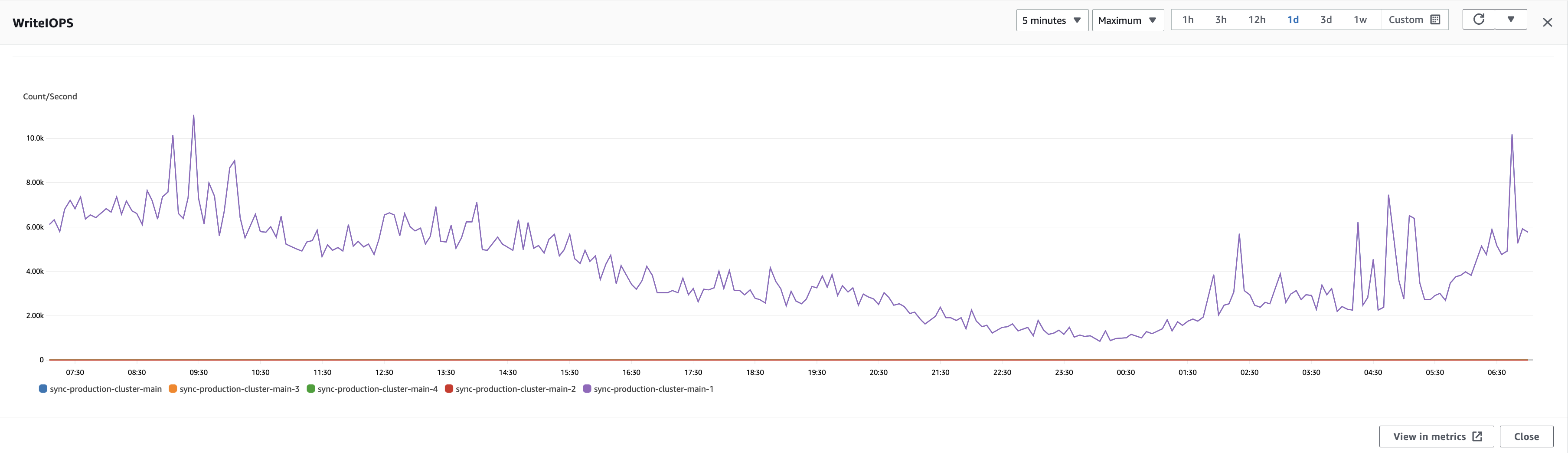
我们开始在 beta 和 staging 集群上进行实验,并且能够实现跨集群 RDS 复制。 但当我们达到生产时,我们的复制过程滞后了很多,并且由于 WriteIOP 数量过多,我们无法赶上。
我们需要找出复制过程滞后的原因。 为了弄清问题的根源,我们首先需要了解三个组成部分:
- 主节点上的二进制日志记录:主节点将其数据的所有更改记录在二进制日志文件中。 这些更改以 SQL 语句或原始二进制数据的形式出现。
- 复制线程:副本端的复制涉及两个主要线程:
- 输入/输出线程:该线程连接到主服务器并获取二进制日志事件。 它将这些事件写入副本的中继日志中。
- SQL线程:该线程从中继日志中读取事件并在副本的数据上执行它们。
- 主从通信:主服务器持续向副本服务器的 I/O 线程发送二进制日志事件。 副本确认收到事件,并通过发送其当前的中继日志坐标来通知主服务器其复制进度。
当我们理解了上面的内容之后,我们就开始询问我们的 SLAVE 使用 SHOW SLAVE STATUS。 这是输出:
Waiting for the slave SQL thread to free enough relay log space
我们做了更多阅读,发现并不是 I/O 无法跟上。 相反,它是一个令人窒息的 SQL 线程,无法以所需的速度应用所有更改。
我们尝试垂直扩展集群,但这无助于加快速度(这意味着额外的计算能力无济于事)。 可以帮助我们的一件事就是妥协 耐用性 在 ACID 属性中。 我们永远不会采取这种方法,但我们很好奇通过调整来运行它 innodb_flush_log_at_trx_commit 数据库的参数。 该参数控制数据刷新到磁盘的速率,从而减少必要的开销。
我们知道通过跨集群复制无法达到 10-15k+ WriteIOP 的速率,但我们的实验向我们表明我们能够赶上 3-4k WriteIOP。
接下来,我们发现了 WriteIOPs 速率最低的窗口。 该窗口于周六早上 4:00 UTC 开始,整个周末该模式保持不变,直到周一再次出现峰值。 所以,这就是我们决定瞄准的窗口。
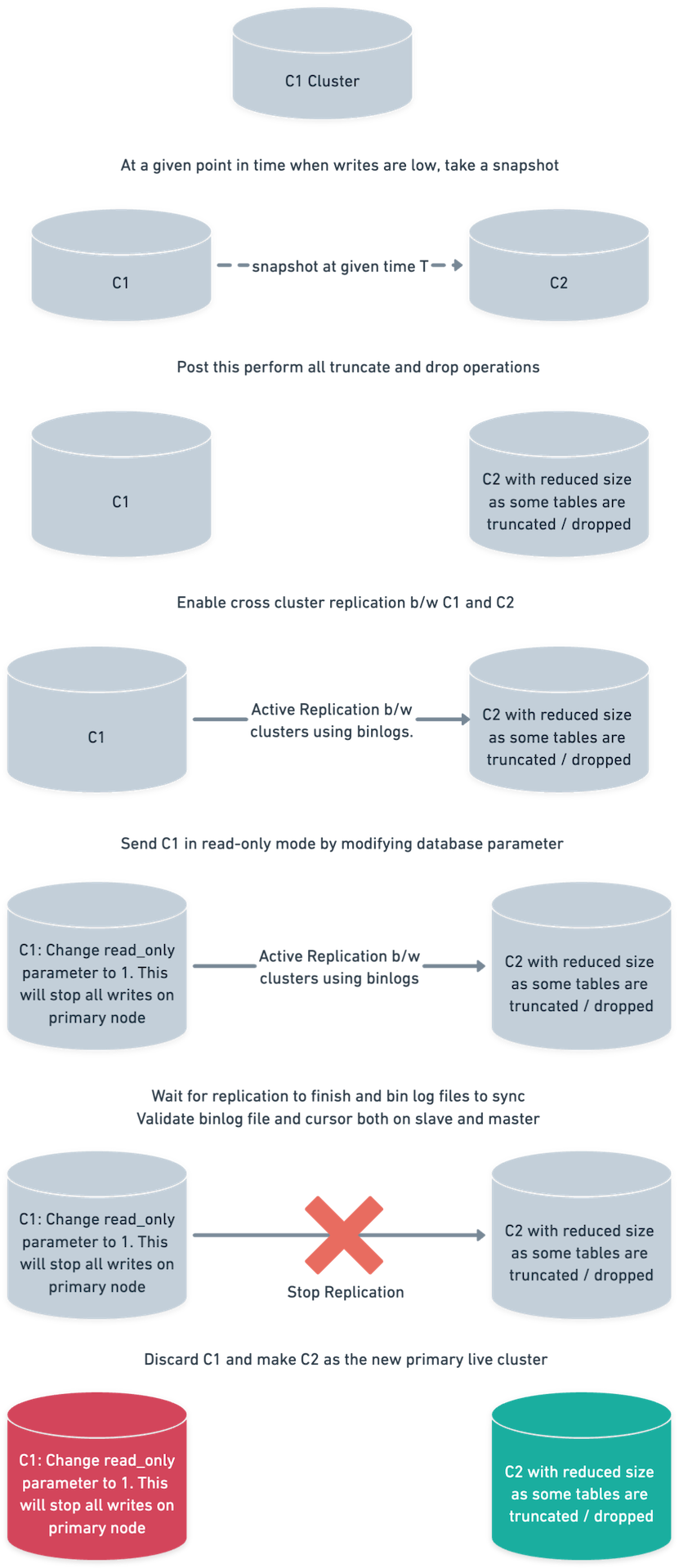
我们的策略:
C1 和 C2 是两个 RDS Aurora 集群。
- 从 C1 的最新快照启动 C2 集群。 如上所述,快照时间为 4:00 UTC。
- 执行所需的
TRUNCATEC2集群上的操作。 我们一直在讨论删除表,但为了安全起见我们进行了截断。DROP通过释放空间也会起到类似的作用。 另请注意,C2 未连接到任何应用程序,因此不应接收任何流量。 - 在 C1 和 C2 集群之间启用跨集群复制。 另外,继续使用记录进度
SHOW MASTER STATUS在 C1 上和SHOW SLAVE STATUS在 C2 上。 - 此时,C1 当前已连接到多个正在进行写入的消费者。
- 持续观察 C2 集群上的指标,以确保其稳定并且复制不会出错。
- 等待复制完全完成。 这
binlog文件和游标在主设备和从设备之间应该几乎重叠。 另外,手动检查 3-4 个高摄取表。 请注意,在我们的示例中,C1 是主设备,C2 是从设备。 - 发送 C1 集群
read-only模式。 改变read-only属性设置为 1,这是一个数据库参数。 为了安全起见,请撤销正在访问数据库的数据库用户的所有写入权限。 - 重新检查复制指标并等待所有
binlog光标重合。 这binlog要检查的游标包括:- 中继日志文件和游标,即 SQL 线程(在 C2 上)。
- 主日志文件和游标,即 I/O 线程(在 C2 上)。
- binlog 文件游标(在 C1 上)。
- 将所有应用程序的流量切换到 C2。
结果

我们能够自由接近 60TB 只需将平台置于只读模式五分钟,即可从最关键的数据库之一释放空间。 这项工作是在 公开宣布的维护窗口,所以时间紧迫,我们必须做好充分准备。
在此过程中,我们还改进了应用程序层,并将摄取率降低至每月约 1.4TB,这一数字势必会随着时间的推移而增加 我们为超过 2500 万用户提供服务。
对我们有什么帮助?
- 我们有一份详尽的清单,并将整个操作分为两天。 第一天,我们启动了 C2 集群,执行了所有截断操作并启用了复制。 我们在第二天进行了实际的数据库切换。
- 我们了解到
TRUNCATE是一个比DROP。 这是因为如果仍然有一些代码路径引用该表,它就不会失败并且可以帮助我们找出答案。 - C1 簇在整个过程的所有点都没有受到影响。 这意味着如果出现任何问题,我们可以返回到该集群,一切都会顺利启动并运行。
- 我们进行了彻底的检查,以确保启用跨集群复制不会导致 C1 和 C2 集群之间的复制错误,因为 C2 已经经历了一系列的操作
TRUNCATE启用复制之前的操作。
下一步是什么?
我们已经开始致力于定义下一代数据库堆栈: 邮差。 也就是说,我们正在积极致力于对数据存储进行分片和分区,并添加对数据隔离的支持,作为存储层本身的保证。 这是一项庞大而复杂的举措,我们需要考虑对整个平台的影响。
有兴趣解决这些挑战吗? 申请于 邮递员职业页面。
由 Dakshraj Sharma 和 Riya Saini 进行技术审查。