
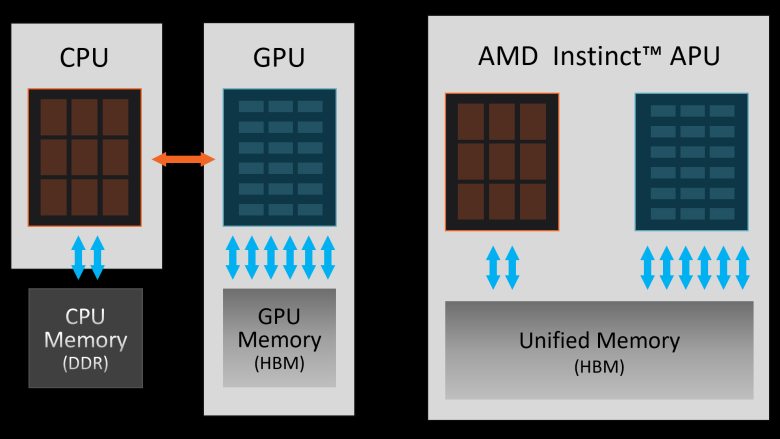
有些工作负载受到当前硬件计算能力的限制。 然而,也有一些负载,当前的加速器对计算能力没有限制,但对数据传输有限制。 在处理器和加速器是分开的并且各自具有自己的存储器的情况下,可能存在在处理器存储器和加速器存储器之间移动数据比计算本身花费更多时间的情况。
AMD 的 Instinct MI300A 是第一个强大的解决方案,它克服了具有自己的内存的 CPU 和具有自己的内存的 GPU 的经典概念,它们通过相对较慢的 PCIe 接口互连。 在MI300A中,内存是统一的、共享的,并且由于统一的地址空间,CPU和GPU部分可以平等地访问它。 因此,如果 GPU 要处理数据,则不必将其从一个内存移动到另一个内存(然后可能将结果返回),而是一切都发生在一个级别上。
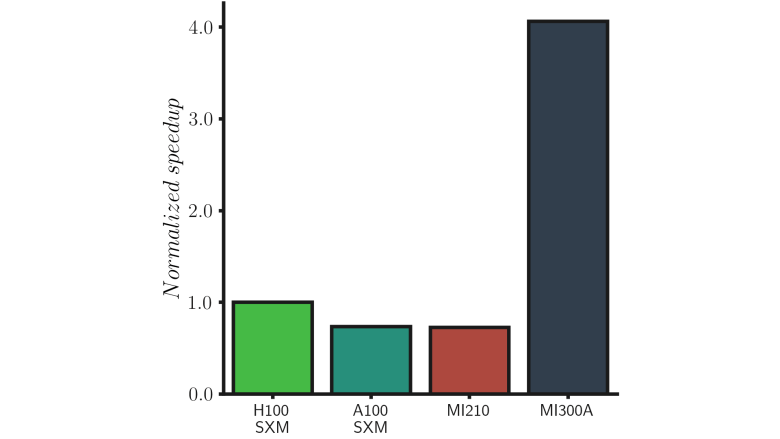
在任务受到数据传输精确限制的情况下,MI300A 的性能变化巨大,可达到基于处理器/加速器的经典解决方案性能的四倍。
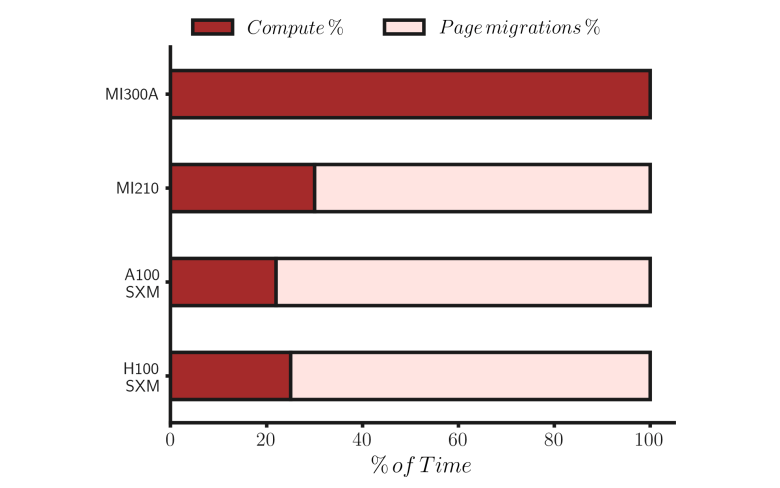
下图显示了各个硬件解决方案将多少任务处理时间用于计算本身(深色)以及多少时间用于数据传输(浅色)。 同时,这个比率也解释了为什么计算能力的提高对此类任务的加速器整体性能影响很小。
Instinct MI300A 是源自最初的 Exascale 异构处理器 (EHP) 又名 Exascale APU 项目的解决方案,该项目(已经)在 2017 年讨论过。回想起来,AMD 如何应对技术开发的变化很有趣。 例如,最初的假设是使用两个四核处理器小芯片,即每个 APU 总共有 8 个核心。 最后,APU 上有 24 个(三个小芯片,每个小芯片有 8 个)。

百兆亿级异构处理器(AMD,2017)
另一方面,HBM内存的发展速度比最初预期的要慢。 这是因为内存制造商决定将其打造为高端解决方案,仅在最强大的加速器(而不是最初旨在广泛适用的产品)上获得回报。 必须使用 HBM3,而不是最初考虑的 HBM4,HBM4 应该分层在低时钟图形芯片上(这样 HBM 就不会烧毁),而 HBM3 最终被经典地放置在“旁边”。 这消除了将图形芯片保持在低时钟(~1 GHz)的需要,并且 AMD 可以提供略高于 2 GHz 的时钟。
直觉
MI100本能
MI210本能
MI250X本能
MI300A本能
米300X指定大角星毕宿五参宿七建筑学cDNACDNA 2CDNA 3中央处理器![]()
![]() 24×禅4
24×禅4![]() 格式PCIePCIeOAM 插座 SH5OAMCU/MS120104
格式PCIePCIeOAM 插座 SH5OAMCU/MS120104
(128)220
(256)228304FP32 贾德76806656
(8192)14080
(16384)1459219456FP64 玉德尔—–INT32罐子—–十。 核心440?416880??速率(最大)1502 MHz 1700 MHz2100 MHz ↓↓↓ T(FL)OPS ↓↓↓FP16
184,6181383980,61300BF16
92,3181383980,61300FP32
23,545,3
22,695,7
47,9122,6163,4FP64
11,522,647,961,381,7INT4
184,6181383??INT8184,618138319602600INT16????INT32????FP8 张量![]()
![]()
![]() 3922,4*
3922,4*
1961,25229,8*
2614,9FP16 张量184,61813831961,2*
980,62614,9*
1307,5BF16 张量92,31813831961,2*
980,62614,9*
1307,5FP32 张量46,145,395,7122,6163,4TF32 张量![]()
![]()
![]() 980,6*
980,6*
490,31307,4*
653,7FP64 张量![]() 45,395,7122,6163,4INT4张量
45,395,7122,6163,4INT4张量![]()
![]()
![]()
![]()
![]() INT8张量
INT8张量
184,61813833922,4*
1961,25229,8*
2614,9 ↑↑↑ T(FL)OPS ↑↑↑TMU第480章缓存??16 MB256 MB 无限缓存公共汽车4096位4096位8192位8192位容量
回忆录32 GB64 GB128 GB128 GB192 GBHBM2,4 GHz3,2 GHz3,2 GHzHBM3 >5 GHz记忆。
透水1229GB/秒1639GB/秒3277GB/秒5,3TB/秒TDP300W300W500W
560W550-760W750W晶体管50毫升。
256亿 291亿 582亿 1460亿 1530亿GPU区域750平方毫米
362 平方毫米 724 平方毫米 660 平方毫米?审判7纳米6纳米6纳米5纳米+6纳米基准20202022202120232023
尽管如此,能源效率还是超出了最初的目标。 Instinct MI300A 实现了每瓦 80-111 GFLOPS(均为双精度通用计算能力),而不是每瓦 50 GFLOPS 的目标。 没有明显变化的是流处理器的数量,原计划为 16,384 个,最终达到 14,592 个。
然而,2017 年完全没有讨论、MI300A 最终做得很好的是 AI 加速。 当谈到双精度的AI计算时,与原计划相比,效率甚至比上一段提到的值高出2倍。
1714991260
#计算 #APU #Instinct #MI300A #的性能比加速器高出 #倍
2024-05-06 05:50:08











