据谷歌称,他们的尖端医疗人工智能 Med-Gemini 在事实准确性、可靠性以及处理复杂的临床推理方面优于 OpenAI 的 GPT-4。
谷歌研究院与 Google DeepMind 合作,发表了一篇新论文(发表于 Arxiv)详细介绍了他们即将推出的专为医疗保健领域设计的人工智能工具 Med-Gemini。 据谷歌研究人员称,尽管目前正在进行研究,Med-Gemini 利用了尖端技术,甚至超过了既定的行业基准。
Med-Gemini 拥有大型多模式模型 (LMM),所有模型均针对不同的目的和应用而设计。 默认情况下,谷歌的 Gemini 模型配备了先进的技术。 他们可以处理来自文本、图像、视频和音频的信息。 Med-Gemini 的效率要高得多,因为它针对所有这些专业进行了微调。
推特/BluechipAI | 基于 zkSync @Bluechip_AI 构建
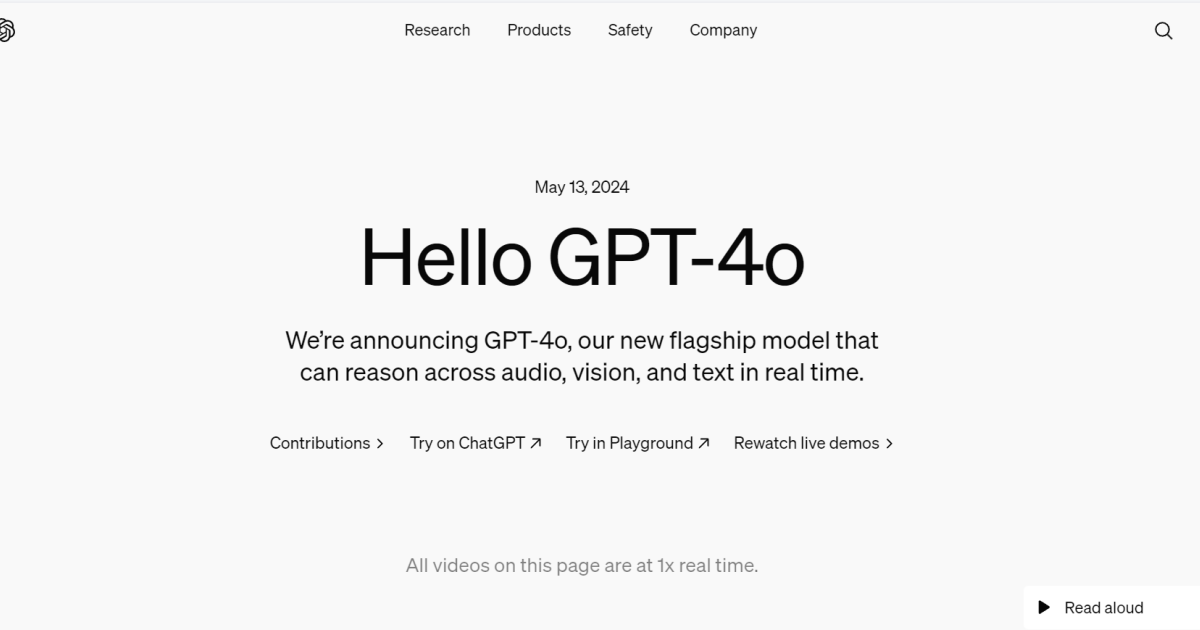
访问、处理信息和自我训练能力的能力: Med-Gemini 利用其网络搜索功能来增强其先进的临床推理能力。 Med-Gemini 展示了其实力,在测试的 14 个医疗基准中,有 10 个在测试中实现了最先进 (SOTA) 的性能,在所有可比指标上都超越了 GPT 模型系列。
推特/亚历克斯·班克斯@thealexbanks
推特/亚历克斯·班克斯@thealexbanks
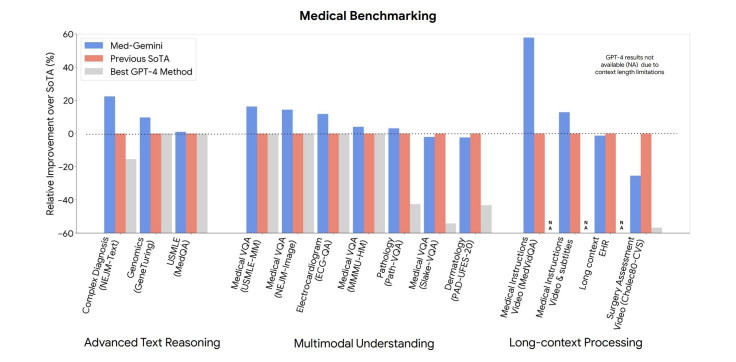
根据 新地图集,Med-Gemini 在 MedQA (USMLE) 基准上的表现脱颖而出,达到了令人印象深刻的 91.1% 准确率。 这一壮举归功于其创新的不确定性引导搜索策略,以 4.5% 的显着优势超越了 Google 的医学 LLM Med-PaLM 2。
简化大量电子病历的分析: 电子健康记录 (EHR) 的冗长特性通常包含重复的文本,可能会阻碍有效的信息检索。 研究人员设计了一项“大海捞针”的任务来展示 Med-Gemini 在应对这一挑战方面的能力。
研究人员使用了一个名为 MIMIC-III(重症监护医疗信息集市)的大型公共数据库。 该数据库包含来自重症监护病房 (ICU) 入院的去识别化健康数据。 旨在测试 Med-Gemini 功能的任务模拟了现实世界的挑战:查明隐藏在大量患者 EHR 数据中的罕见或微妙的医疗状况、症状或程序。
Med-Gemini 在测试中表现良好,展示了其从患者记录中提取所有提及目标医疗问题的能力。 此外,它超越了简单的检索,通过评估每个提及的相关性、对它们进行分类,并最终确定患者的病史。 这个过程也凸显了Med-Gemini的推理能力。
还有什么可期待的?
虽然 Med-Gemini 的能力无可否认令人印象深刻,但研究人员承认还有改进的空间。 尽管如此,它的性能预示着人工智能驱动的医疗保健应用前景光明。
此外,这家搜索巨头表示,在开发过程中将注重公平性和隐私性。 研究人员表示:“隐私方面的考虑尤其需要植根于管理和保护患者信息的现有医疗保健政策和法规中。”
研究人员承认人工智能医疗系统无意中延续历史偏见和不平等的风险,并认识到公平的重要性。 这不仅仅是一个理论上的问题;而是一个问题。 最近的例子,比如微软的人工智能工具 Copilot, 批评的 为了产生反犹太主义的刻板印象,强调潜在的危害。
如果不加以解决,这些偏差可能会导致模型性能不平等,并对医疗保健中的边缘患者群体产生潜在的有害后果。
1715173718
2024-05-08 12:43:07