

人类学/本杰·爱德华兹
到目前为止,Anthropic 以外的人似乎都对此印象深刻。“这个模型真的非常好。” 写道 独立 AI 研究员 Simon Willison 在谈到 X 时表示:“我认为这是新的最佳整体模型(而且速度更快,价格只有 Opus 的一半,类似于从 GPT-4 Turbo 到 GPT-4o 的跳跃)。”
正如我们 写于之前,大型语言模型 (LLM) 的基准测试很麻烦,因为它们可能经过精心挑选,而且通常无法捕捉到使用机器生成几乎任何可以想到的主题的输出的感觉和细微差别。但根据 Anthropic 的说法,Claude 3.5 Sonnet 在某些基准测试中与 GPT-4o 和 Gemini 1.5 Pro 等竞争对手的模型相匹配或优于它们,例如 莫尔曼·卢 (本科水平的知识), GSM8K (小学数学),以及 人力评估 (编码)。
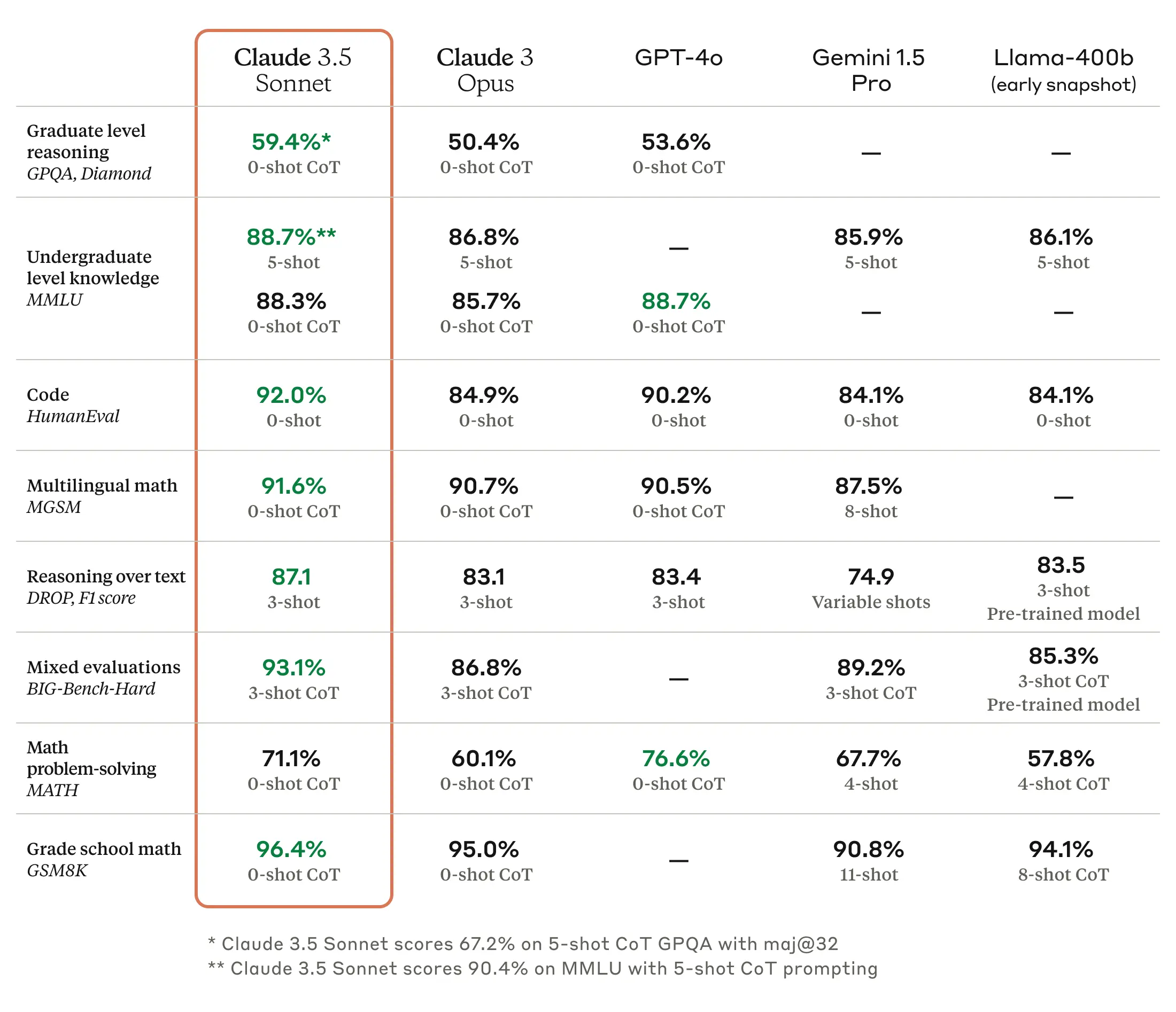
放大 / Anthropic 提供的 Claude 3.5 Sonnet 基准。
如果这一切让你眼花缭乱,那也没关系;这对研究人员来说很有意义,但对其他人来说主要是营销。一个更有用的绩效指标来自我们所谓的“维贝马克斯“(首先在这里创造!)这是主观的、不严格的总体感受,通过 LMSYS 的 Chatbot Arena 等网站上的竞争使用情况来衡量。Claude 3.5 Sonnet 模型是 目前正在评估,现在判断其表现如何还为时过早。
Claude 3.5 Sonnet 也是一个多模式 AI 模型,可以接受图像形式的视觉输入,据报道,新模型在一系列视觉理解测试中表现出色。
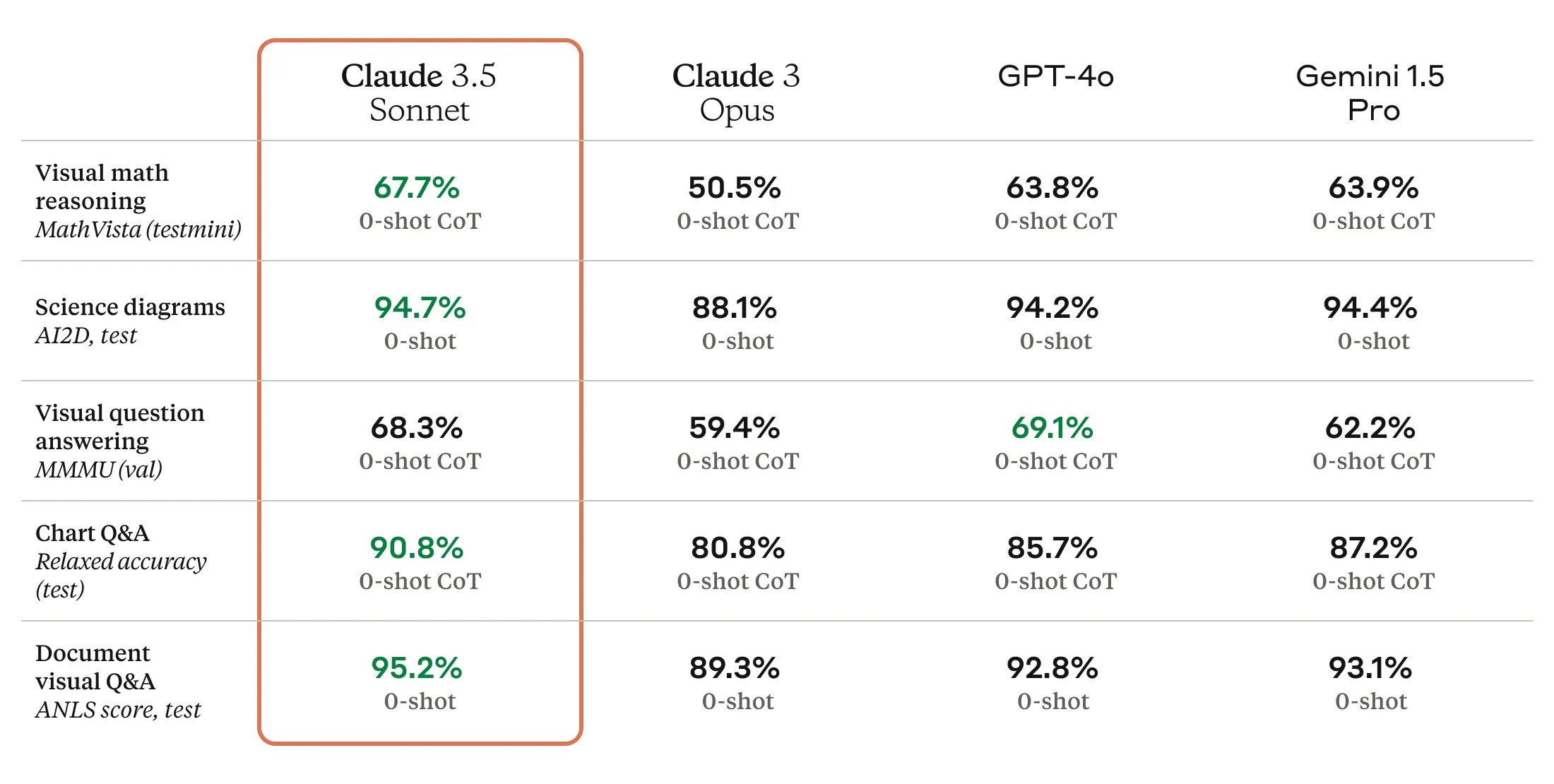
放大 / Anthropic 提供的 Claude 3.5 Sonnet 基准。
2024-06-20 21:04:59
1719194097



:quality(70):focal(1422x727:1432x737)/cloudfront-eu-central-1.images.arcpublishing.com/liberation/2JX6TKKZ5REG7JL5IJIK3FBWFY.jpg)







