
XML 处理在 15 年前风靡一时; 虽然现在它不再那么突出,但在某些应用领域中它仍然是一项重要任务。 在这篇文章中,我将比较 Go、Python 和 C 中流处理大型 XML 文件的速度,并最终使用一个新的最小模块,该模块使用 C 来加速 Go 的这项任务。 这篇文章中显示的所有代码都可用 在此 GitHub 存储库中 新的 Go 模块 在这儿。
XML 流处理是什么意思?
首先,让我们更详细地定义当前的问题。 粗略地说,我们可以通过两种方式处理文件中的数据:
- 将整个文件一次性读入内存,然后在内存中处理数据。
- 分块读取文件,处理每个卡盘,而无需在任何给定时间将整个数据存储在内存中。
在很多方面,(1) 更方便,因为我们可以轻松返回到文件的任何部分。 然而,在某些情况下(2)是必不可少的; 特别是当文件非常大时。 这是哪里 溪流 如果我们的输入文件是 500 GiB,我们不太可能将其读入内存,并且必须分批处理它。 即使对于理论上可以放入 RAM 的较小文件,完整读取它们也并不总是一个好主意; 这会显着增加活动堆大小,并可能导致垃圾收集语言的性能问题。
任务
对于这个基准测试,我使用 XML生成器 创建一个 230 MiB XML 文件。 文件的一小部分可能如下所示:
-
United States
1
duteous nine eighteen
Creditcard
...
任务是找出“Africa”在数据中出现了多少次
基线 – 使用Go标准库
让我们从基线实现开始 – 使用标准库的
编码/xml 包裹。 虽然包裹的 解组 模式将一次性解析整个文件,它也可以用于逐个处理 XML 令牌并选择性地解析感兴趣的元素。 这是代码:
package main
import (
"encoding/xml"
"fmt"
"io"
"log"
"os"
"strings"
)
type location struct {
Data string `xml:",chardata"`
}
func main() {
f, err := os.Open(os.Args[1])
if err != nil {
log.Fatal(err)
}
defer f.Close()
d := xml.NewDecoder(f)
count := 0
for {
tok, err := d.Token()
if tok == nil || err == io.EOF {
// EOF means we're done.
break
} else if err != nil {
log.Fatalf("Error decoding token: %s", err)
}
switch ty := tok.(type) {
case xml.StartElement:
if ty.Name.Local == "location" {
// If this is a start element named "location", parse this element
// fully.
var loc location
if err = d.DecodeElement(&loc, &ty); err != nil {
log.Fatalf("Error decoding item: %s", err)
}
if strings.Contains(loc.Data, "Africa") {
count++
}
}
default:
}
}
fmt.Println("count =", count)
}
我确保在处理大文件时仔细检查该程序的内存使用量是否保持有限且较低 – 在处理 230 MiB 输入文件时最大 RSS 低于 7 MiB。 我正在使用以下命令对本文中介绍的所有程序进行验证 /usr/bin/时间 -v 在 Linux 上。
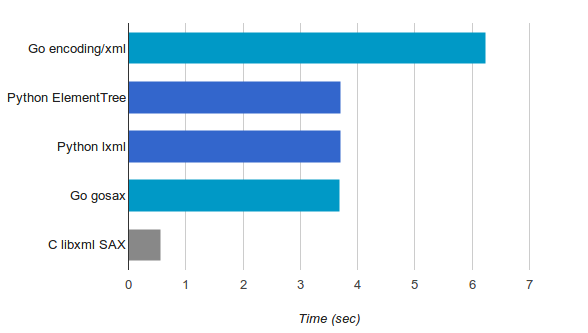
该程序需要 6.24 秒来处理整个文件并打印出结果。
Python实现
第一个 Python 实现使用 xml.etree.ElementTree 标准库中的模块:
import sys
import xml.etree.ElementTree as ET
count = 0
for event, elem in ET.iterparse(sys.argv[1], events=("end",)):
if event == "end":
if elem.tag == 'location' and elem.text and 'Africa' in elem.text:
count += 1
elem.clear()
print('count =', count)
这里的关键是 elem.clear() 称呼。 它确保每个元素在完全解析后被丢弃,因此内存使用量不会随着文件的大小线性增长(除非文件是病态的)。 这个程序需要 3.7 秒来处理整个文件 – 比我们的 Go 程序快得多。 这是为什么?
虽然 Go 程序使用 100% Go 代码来完成任务(编码/xml 完全用 Go 实现),Python 程序使用 C 扩展(大部分
元素树 用 C 编写)用 C 封装快速 XML 解析器 – libexpat。 这里的大部分工作是用 C 完成的,它比 Go 更快。 性能 编码/xml 进一步讨论于
这个问题,虽然它是一个旧的,并且从那时起性能已经进行了一些优化。
Python 的另一个 XML 解析库是 lxml,它使用 库文件 下。 这是使用 lxml 的 Python 版本:
import sys
from lxml import etree
count = 0
for event, elem in etree.iterparse(sys.argv[1], events=("end",)):
if event == "end":
if elem.tag == 'location' and elem.text and 'Africa' in elem.text:
count += 1
elem.clear()
print('count =', count)
这看起来与之前的版本非常相似,这是故意的。 lxml 有一个 树– 兼容的API,使从标准库的过渡更加顺利。 对于我们的 230 MiB 文件,此版本也需要大约 3.7 秒。
我在这里包含 lxml 的原因是它的运行速度比
xml.etree.ElementTree 当读取整个文件时,对于我们特定的文件大小。 我想强调的是,这超出了我的实验范围,因为我只关心流处理。 使用 lxml 成功处理 500 GiB 文件的唯一方法(据我所知!)是使用
迭代解析。
它能跑多快?
根据此处提供的测量结果,以流方式解析大型 XML 文件时,Go 比 Python 慢约 68%。 虽然 Go 通常编译成的代码比纯 Python 快得多,但 Python 实现有高效 C 库的支持,很难与之竞争。 我很好奇理论上它能有多快。
为了回答这个问题,我使用纯 C 和 libxml 实现了相同的程序,它有一个 萨克斯API。 我不会把它完整地粘贴在这里,因为它更长,但你可以找到 GitHub 上的完整源代码。 处理我们的 230 MiB 输入文件只需要 0.56 秒,考虑到其他结果,这非常令人印象深刻,但也并不令人意外。 毕竟这是C。
你可能会想 – 如果lxml底层使用libxml,为什么它比纯C版本慢这么多? 答案是Python 调用开销。 lxml 版本回调到 Python 对于每个解析的元素,这会产生巨大的成本。 另一个原因是我的 C 实现实际上并不解析元素 – 它只是一个简单的基于事件的状态机,因此需要完成的额外工作较少。
使用 Go 中的 libxml
回顾一下我们目前的进展:
- 基于底层 C 实现的 Python 库比纯 Go 更快。
- 纯 C 的速度仍然更快。
我们有两个选择:我们可以尝试优化 Go 的 编码/xml
包,或者我们可以尝试用 Go 包装一个快速的 C 库。 虽然前者是一个值得实现的目标,但它需要付出巨大的努力,应该作为单独帖子的主题。 在这里,我会选择后者。
在网上搜索时,我发现了一些 libxml 的包装器。 两个似乎颇受欢迎且维护良好的项目是
和 https://github.com/moovweb/gokogiri。 不幸的是,这些(或我发现的其他绑定)都没有公开 libxml 的 SAX API; 相反,他们专注于 DOM API,其中整个文档由底层库解析并返回一棵树。 如上所述,我们需要SAX接口来处理大文件。
戈萨克斯
是时候推出我们自己的了 🙂 我写了 戈萨克斯 模块,它使用 Cgo 调用 libxml 并公开 SAX 接口。 在 Cgo 中实现它是一个有趣的练习,因为它需要一些重要的概念,例如使用 C 注册 Go 回调。
这是我们使用 gosax 的程序版本:
package main
import (
"fmt"
"os"
"strings"
"github.com/eliben/gosax"
)
func main() {
counter := 0
inLocation := false
scb := gosax.SaxCallbacks{
StartElement: func(name string, attrs []string) {
if name == "location" {
inLocation = true
} else {
inLocation = false
}
},
EndElement: func(name string) {
inLocation = false
},
Characters: func(contents string) {
if inLocation && strings.Contains(contents, "Africa") {
counter++
}
},
}
err := gosax.ParseFile(os.Args[1], scb)
if err != nil {
panic(err)
}
fmt.Println("counter =", counter)
}
正如您所看到的,它实现了一个状态机,该状态机会记住位于 地点 元素,在其中检查字符数据。 该程序需要 4.03 秒来处理我们的输入文件。 不错! 但我们可以做得更好一点 经过一些优化
我设法将其降低到 3.68 秒——与 Python 实现的速度大致相同!
恕我直言,这里大致相似的运行时间纯属巧合,因为 Python 程序与我的方法不同,因为它们公开了比纯 SAX 更高级别的 API。 回想起那个 迭代解析 返回一个解析后的元素,我们可以访问它 文本 属性等。在 gosax 中,我们必须更多地手动执行此操作。 自从 Cgo和Go之间的调用成本相当高,这里有一个 gosax 的优化机会。 我们可以在 C 中做更多的工作 – 解析完整的元素,并将其完全返回给 Go。 这会将工作从 Go 端转移到 C 端,并减少跨语言调用的数量。 但这是另一天的任务。
结论
嗯,这很有趣:-) 这里描述的同一个简单任务有 5 种不同的实现,使用 3 种不同的编程语言。 以下是我们获得的速度测量结果的摘要:
Python 的性能故事一直是——“它可能足够快,在极少数情况下不够快,请使用 C 扩展”。 在 Go 中,情况有些不同:在大多数情况下,Go 编译器生成相当快的代码。 纯 Go 代码明显比 Python 快,而且通常比 Java 快。 即便如此,偶尔为了性能而深入研究 C 或 C++ 可能会很有用,在这些情况下,Cgo 是一个很好的方法。
很明显 编码/xml 需要一些关于表现的工作,但在那之前 – 还有很好的选择! DOM API 可以利用 libxml 的速度,现在 SAX API 也可以利用 libxml 的速度。 从长远来看,我相信认真的表现会起作用 编码/xml 可以使其比 libxml 包装器运行得更快,因为它可以消除 C-to-Go 调用的高成本。






:quality(70):focal(930x670:940x680)/cloudfront-eu-central-1.images.arcpublishing.com/liberation/AMNC7W6K2NGF5IVRPEIIU4DWVY.jpg)



