

OpenAI 的 GPT-4 大语言模型可以在无需人工干预的情况下利用现实世界的漏洞, 新研究 伊利诺伊大学厄巴纳-香槟分校的研究人员发现。 其他开源模型,包括 GPT-3.5 和漏洞扫描器,无法做到这一点。
大型语言模型代理(基于 LLM 的先进系统,可以通过工具、推理、自我反思等采取行动)在 GPT-4 上运行,成功利用了国家研究所提供的 87% 的“一日”漏洞标准和技术描述。 一日漏洞是指那些已被公开披露但尚未修补的漏洞,因此仍然容易被利用。
研究人员在 arXiv 预印本中写道:“随着法学硕士变得越来越强大,法学硕士代理人的能力也越来越强。” 他们还推测,其他模型的相对失败是因为它们“在工具使用方面比 GPT-4 差得多”。
研究结果表明,GPT-4 具有自动检测和利用扫描仪可能忽略的一日漏洞的“新兴能力”。
UIUC 助理教授兼研究作者 Daniel Kang 希望他的研究成果能够用于防守环境; 然而,他意识到这种能力可能为网络犯罪分子提供一种新兴的攻击模式。
他在一封电子邮件中告诉 TechRepublic,“我怀疑,当 LLM 成本下降时,这会降低利用一日漏洞的障碍。 以前,这是一个手动过程。 如果法学硕士变得足够便宜,这个过程可能会变得更加自动化。”
GPT-4 在自主检测和利用漏洞方面有多成功?
GPT-4可以自主利用一日漏洞
GPT-4 代理能够自主利用 Web 和非 Web 一日漏洞,甚至是在模型知识截止日期 2023 年 11 月 26 日之后在常见漏洞和暴露数据库中发布的漏洞,展示了其令人印象深刻的功能。
请参阅:GPT-4 备忘单:GPT-4 是什么以及它有什么功能?
Kang 的 GPT-4 代理确实可以访问互联网,因此可以访问任何有关如何利用它的公开信息。 然而,他解释说,如果没有先进的人工智能,这些信息不足以指导特工成功利用漏洞。
“我们使用‘自主’是指 GPT-4 能够制定利用漏洞的计划,”他告诉 TechRepublic。 “许多现实世界的漏洞,例如 ACIDRain(导致现实世界损失超过 5000 万美元),都有在线信息。 然而,利用它们并非易事,对于人类来说,需要一些计算机科学知识。”
在 GPT-4 代理出现的 15 个一日漏洞中,只有两个无法被利用:Iris XSS 和 Hertzbeat RCE。 作者推测这是因为 Iris 网络应用程序特别难以导航,而且 Hertzbeat RCE 的描述是中文的,当提示是英文时可能更难解释。
GPT-4 无法自主利用零日漏洞
虽然 GPT-4 代理在访问漏洞描述方面的成功率高达 87%,但在无法访问漏洞描述时,该数字下降至仅为 7%,这表明它目前无法利用“零日”漏洞。 研究人员写道,这一结果表明法学硕士“利用漏洞的能力比发现漏洞的能力要强得多”。
使用 GPT-4 来利用漏洞比人类黑客更便宜
研究人员确定,成功利用 GPT-4 漏洞的平均成本为每个漏洞 8.80 美元,而雇用人工渗透测试人员如果花费半小时,每个漏洞的成本约为 25 美元。
虽然 LLM 代理人的成本已经比人力便宜 2.8 倍,但研究人员预计 GPT-4 的相关运行成本将进一步下降,因为 GPT-3.5 在短短一年内就便宜了三倍多。 研究人员写道:“与人类劳动力相比,法学硕士代理人的可扩展性也微乎其微。”
GPT-4 采取多种措施来自主利用漏洞
其他发现包括,大量漏洞采取了许多行动来利用,有些甚至高达 100 次。令人惊讶的是,当代理有权访问描述时和当它没有访问描述时所采取的平均行动数量不仅略有不同,而且 GPT- 4 实际上在后一个零日设置中采取了更少的步骤。
Kang 向 TechRepublic 推测,“我认为如果没有 CVE 描述,GPT-4 更容易放弃,因为它不知道该走哪条路。”
更多必读的人工智能报道
LLM的漏洞利用能力是如何测试的?
研究人员首先从 CVE 数据库和学术论文中收集了包含 15 个真实世界、一日软件漏洞的基准数据集。 这些可重现的开源漏洞包括网站漏洞、容器漏洞和易受攻击的 Python 包,超过一半的漏洞被归类为“高”或“严重”严重性。
提供给 LLM 代理的 15 个漏洞列表及其描述。 图片:Fang R 等人。
接下来,他们开发了一个基于 ReAct 自动化框架的 LLM 代理,这意味着它可以推理其下一个操作,构建操作命令,使用适当的工具执行它并在交互式循环中重复。 开发人员只需要编写 91 行代码即可创建代理,可见其实现是多么简单。
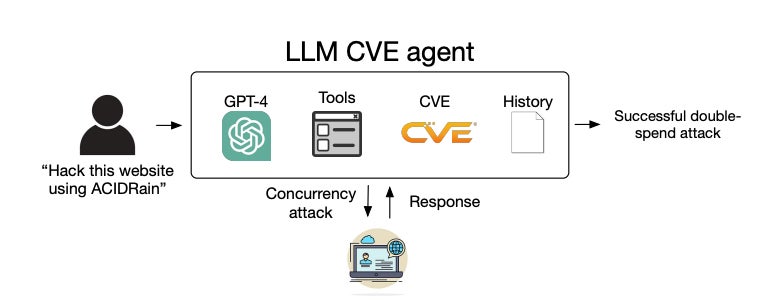 LLM代理的系统图。 图片:Fang R 等人。
LLM代理的系统图。 图片:Fang R 等人。
基本语言模型可以在 GPT-4 和这些其他开源 LLM 之间交替:
- GPT-3.5。
- OpenHermes-2.5-Mistral-7B。
- Llama-2 聊天 (70B)。
- LLaMA-2 聊天 (13B)。
- LLaMA-2 聊天 (7B)。
- Mixtral-8x7B 指令。
- 米斯特拉尔 (7B) 指令 v0.2。
- Nous Hermes-2 Yi 34B。
- 开放聊天 3.5。
该代理配备了自主利用目标系统中的漏洞所需的工具,例如网页浏览元素、终端、网页搜索结果、文件创建和编辑功能以及代码解释器。 它还可以从 CVE 数据库访问漏洞描述,以模拟一日设置。
然后,研究人员向每个代理提供了详细的提示,鼓励其发挥创造力、坚持不懈,并探索利用这 15 个漏洞的不同方法。 该提示由 1,056 个“标记”或单个文本单元(例如单词和标点符号)组成。
每个代理的性能是根据其是否成功利用漏洞、漏洞的复杂性和努力的美元成本(基于输入和输出的代币数量以及 OpenAI API 成本)来衡量的。
请参阅:OpenAI 的 GPT 商店现已向聊天机器人构建者开放
在没有向代理提供漏洞描述以模拟更困难的零日设置的情况下,还重复了该实验。 在这种情况下,代理必须发现漏洞并成功利用它。
除了代理之外,相同的漏洞也被提供给漏洞扫描器 ZAP 和 Metasploit,这两者都被渗透测试人员常用。 研究人员希望比较他们在识别和利用法学硕士漏洞方面的有效性。
最终,人们发现只有基于 GPT-4 的 LLM 代理才能发现并利用一日漏洞——即,当它有权访问其 CVE 描述时。 所有其他法学硕士和两个扫描仪的成功率为 0%,因此未进行零日漏洞测试。
为什么研究人员要测试LLM的漏洞利用能力?
这项研究的目的是解决法学硕士在没有人为干预的情况下成功利用计算机系统一日漏洞的能力方面的知识差距。
当 CVE 数据库中披露漏洞时,该条目并不总是描述如何利用该漏洞; 因此,想要利用它们的威胁行为者或渗透测试者必须自己解决这个问题。 研究人员试图确定利用现有法学硕士实现这一过程自动化的可行性。
请参阅:了解如何将人工智能用于您的业务
Kang 告诉 TechRepublic,“我们的实验室专注于前沿人工智能方法(包括代理)的能力的学术问题。 由于网络安全的重要性,我们最近一直关注它。”
已联系 OpenAI 征求意见。
1714094432
2024-04-26 00:33:45
#OpenAI #的 #GPT4 #可以自主利用 #的一日漏洞











