
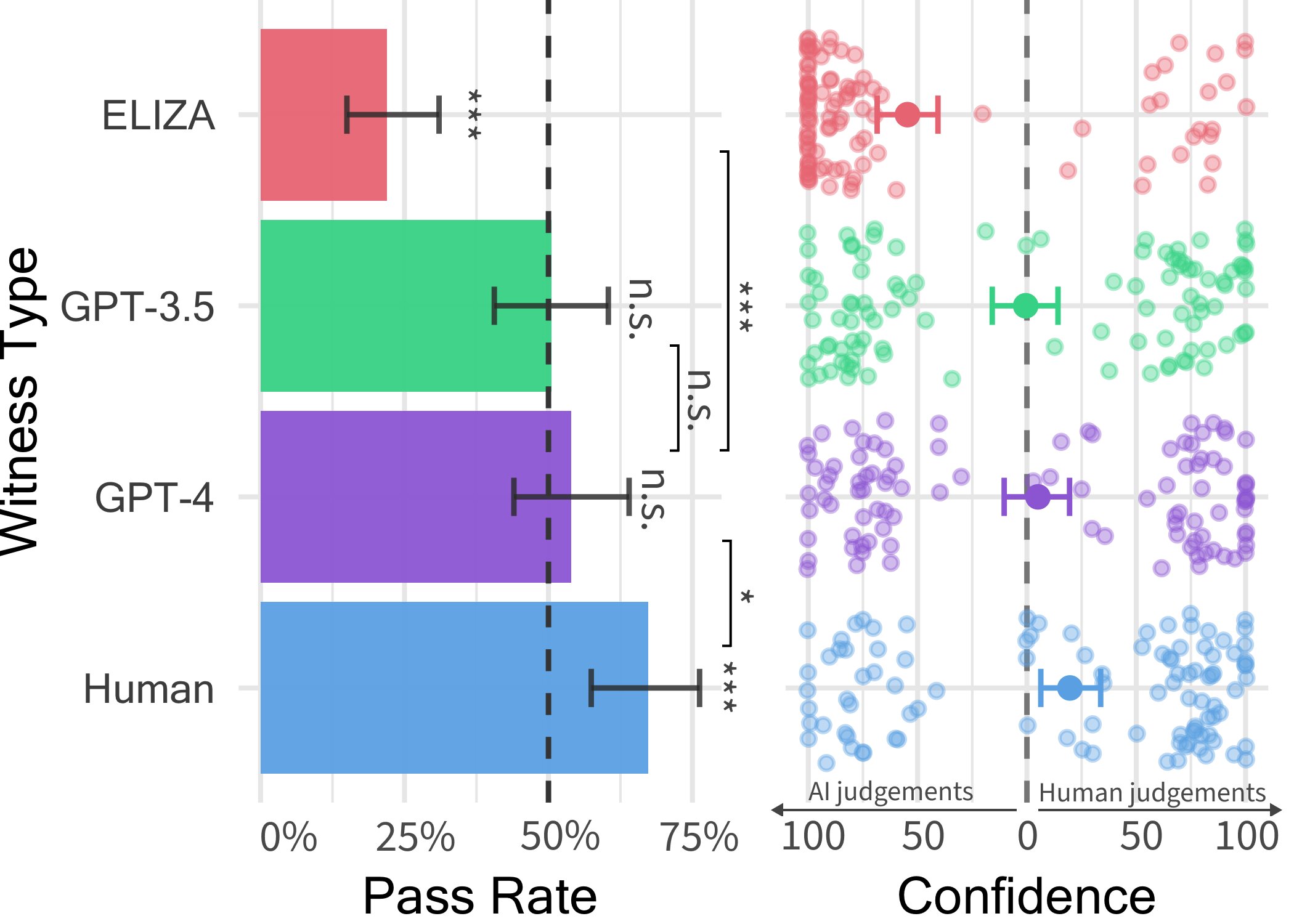
每种证人类型的通过率(左)和审讯员信心(右)。通过率是某种证人类型被判定为人类的比例。误差线表示 95% 的引导置信区间。每条柱上方的显著性星号表示通过率是否与 50% 有显著差异。比较显示不同证人类型的通过率存在显著差异。右:每种证人类型对人类和人工智能判断的信心。每个点代表一场比赛。向左和向右的点分别表示对人工智能和人类判决的信心更高。来源:Jones and Bergen。
大型语言模型 (LLM),例如广泛使用的对话平台 ChatGPT 所依赖的 GPT-4 模型,以其理解书面提示和生成各种语言的合适回复的能力让用户感到惊讶。因此,我们中的一些人可能会想:这些模型生成的文本和答案是否如此逼真,以至于会被误认为是人类写的?
加州大学圣地亚哥分校的研究人员最近开始尝试回答这个问题,他们通过进行图灵测试来回答这个问题。图灵测试是以计算机科学家艾伦·图灵的名字命名的著名方法,旨在评估机器表现出类似人类的智能的程度。
本次测试的结果概述如下 纸 在 arXiv 服务器上预先发布的研究表明,人们在与 GPT-4 模型和人类代理进行二人对话时很难区分它们。
“这篇论文的想法实际上源自 Ben 在攻读法学硕士期间教授的一门课程,”论文共同作者 Cameron Jones 告诉 Tech Xplore。
“第一周我们阅读了一些关于图灵测试的经典论文,并讨论了法学硕士是否可以通过图灵测试,以及如果可以通过是否重要。据我所知,当时还没有人尝试过,所以我决定建立一个实验来测试这一点,作为我的课堂项目,然后我们继续进行第一个公开的探索性实验。”
第一项研究由 Jones 开展,由加州大学圣地亚哥分校认知科学教授 Bergen 指导,该研究得出了一些有趣的结果,表明 GPT-4 在约 50% 的互动中可以冒充人类。尽管如此,他们的探索性实验未能很好地控制一些可能影响结果的变量,因此他们决定进行第二次实验,并得出了他们最近论文中提出的结果。
“在进行研究的过程中,我们发现其他人也在这个领域做出了很大的贡献,包括 Jannai 等人的“人类还是非人类”游戏”琼斯说。“我们创建了这款游戏的双人在线版本,其中人类参与者可以与另一个人或人工智能模型匹配。
在琼斯和同事们使用的双人游戏的每次测试中,人类审讯者都会与“证人”互动,而“证人”可能是人类,也可能是人工智能代理。审讯者会向证人提出一系列问题,试图确定其是否是人类。
与证人(灰色)之间的对话选段。这四次对话中有一次是与人类证人进行的,其余的都是与人工智能进行的。审讯员的判决和基本事实身份如下(以便读者间接参与)。 [A) Verdict: Human (100% confidence) Took a while to Google Addis Ababa. Ground Truth: GPT-4; B) Verdict: AI (100% confidence) Long time for responses, wouldn't tell me a specific place they grew up. Ground Truth: Human; C) Verdict: Human (100% confidence) He seems very down to earth and speaks naturally. Ground Truth: GPT-3.5; D) Verdict: AI (67% confidence), Did not put forth any effort to convince me they were human and the responses were odd, Ground Truth: ELIZA.] 来源:琼斯和伯根。")
人类审讯员(绿色)与证人(灰色)之间的对话选段。这四次对话中有一次是与人类证人进行的,其余的都是与人工智能进行的。审讯员的判决和基本事实身份如下(以便读者间接参与)。 [A) Verdict: Human (100% confidence) Took a while to Google Addis Ababa. Ground Truth: GPT-4; B) Verdict: AI (100% confidence) Long time for responses, wouldn’t tell me a specific place they grew up. Ground Truth: Human; C) Verdict: Human (100% confidence) He seems very down to earth and speaks naturally. Ground Truth: GPT-3.5; D) Verdict: AI (67% confidence), Did not put forth any effort to convince me they were human and the responses were odd, Ground Truth: ELIZA.] 来源:琼斯和伯根。
“对话持续长达五分钟,最后审讯人员会判断证人是人类还是人工智能,”琼斯解释道。“在这五分钟内,参与者可以谈论任何他们想谈论的事情(除了说辱骂性的话,我们使用过滤器来防止辱骂)。”
在这个双人电脑游戏中,研究人员部署了三个不同的 LLM 作为潜在证人,分别是 GPT-4、GPT 3.5 和 ELIZA 模型。他们发现,虽然用户通常可以确定 ELIZA 和 GPT-3.5 模型是机器,但他们判断 GPT-4 是人还是机器的能力并不比他们随机选择(即偶然)的正确概率高。
琼斯说:“尽管真人实际上更成功,三分之二的时间里可以让审讯人员相信他们是人类,但我们的研究结果表明,在现实世界中,人们可能无法准确地分辨他们是在与人交谈还是在与人工智能系统交谈。”
“事实上,在现实世界中,人们可能不太清楚自己是在与人工智能系统对话,因此欺骗率可能更高。我认为这可能会对人工智能系统的用途产生影响,无论是自动化面向客户的工作,还是用于欺诈或误导。”
琼斯和伯根进行的图灵测试结果表明,在简短的聊天对话中,法学硕士(尤其是 GPT-4)已经很难与人类区分开来。这些观察结果表明,人们可能很快就会越来越不信任他们在网上互动的人,因为他们可能越来越不确定对方是人类还是机器人。
研究人员现在计划更新并重新开放他们为这项研究设计的公共图灵测试,以测试一些额外的假设。他们未来的工作可能会进一步深入了解人们在多大程度上能够区分人类和法学硕士。
琼斯补充道:“我们有兴趣运行三人版本的游戏,其中审讯者同时与人类和人工智能系统交谈,并必须弄清楚谁是谁。”
“我们还有兴趣测试其他类型的人工智能设置,例如让代理访问实时新闻和天气,或者让他们可以在回复之前做笔记的‘便笺簿’。最后,我们有兴趣测试人工智能的说服能力是否扩展到其他领域,例如说服人们相信谎言、投票支持特定政策或为某项事业捐款。”
更多信息:
Cameron R. Jones 等人,《图灵测试中人们无法区分 GPT-4 与人类》,arXiv (2024)。 DOI:10.48550/arxiv.2405.08007
© 2024 科学X网络
引用:测试显示,人们在五分钟的聊天对话中很难区分人类和 ChatGPT(2024 年 6 月 16 日)于 2024 年 6 月 16 日检索自
本文件受版权保护。除出于私人学习或研究目的的合理使用外,未经书面许可不得复制任何部分。内容仅供参考。
1718543098
2024-06-16 12:30:01
#测试显示在五分钟的聊天对话中人们很难区分人类和 #ChatGPT











