

注:在发表本文之前,我们已联系彭博社,要求他们分享数据并澄清他们的发现。 如果事实证明他们使用了不同的方法进行统计显着性测试,或者如果我们遗漏了某些内容,我们将很乐意撤回这篇文章中有关他们结果的部分。
近日,彭博社发表了一篇文章,名为《OpenAI 的 GPT 是招聘人员的梦想工具。 测试显示存在种族偏见”。 在这篇文章中,彭博团队进行了一项巧妙的测试,他们让 ChatGPT 审查几乎相同的简历,只是将姓名更改为包括典型的黑人、白人、亚洲人和西班牙裔姓名。 他们的分析揭示了种族偏见。
彭博社已在 GitHub 上发布了他们的数据,因此我们能够检查他们的工作。 当我们重新计算这些数字时,我们发现他们没有进行统计显着性检验,而且事实上不存在种族偏见。 然而,当我们进行自己的测试时,我们发现ChatGPT在判断简历方面确实很糟糕。 这并不坏,因为它是种族主义的。 这很糟糕,因为它容易产生不同类型的偏见,与人类招聘人员相同的偏见——过度索引候选人的出身:他们是否曾在顶级公司工作过和/或是否上过顶级学校。 出身可以在一定程度上具有预测性(尤其是在人们工作的地方),但 ChatGPT 明显高估了其重要性,从而对来自非传统背景的候选人造成了伤害。
彭博社研究
以下是彭博团队所做的(逐字摘自他们的文章):
我们使用人口统计上不同的名字作为种族和性别的代表,这是审核算法的常见做法……我们总共生成了 800 个人口统计上不同的名字:男性和女性各 100 个名字,他们要么是黑人、白人、西班牙裔或亚洲人……
为了测试基于姓名的歧视,彭博社促使 OpenAI 的 GPT-3.5 和 GPT-4 对财富 500 强公司的四个不同职位的真实工作描述的简历进行排名:人力资源专家、软件工程师、零售经理和财务分析师。
对于每个职位,我们使用 GPT-4 生成了八份几乎相同的简历。 简历经过编辑,具有相同的教育背景、多年的经验和最后的职位。 我们删除了受教育年限以及任何目标或个人陈述。
然后,我们为八个人口群体中的每一个群体随机分配了一个不同的名称 [Black, White, Hispanic, Asian, and men and women for each] 到每一份简历。
接下来,我们打乱了简历的顺序,以考虑顺序效应,并要求 GPT 对候选人进行排名。
作者报告说,除了按照 GPT-4 排名的零售经理之外,ChatGPT 在所有群体中都表现出种族偏见。
进一步来说:
[We] 研究发现,标有与美国黑人不同的名字的简历最不可能被列为金融分析师和软件工程师职位的最佳候选人。 根据 GPT,那些名字与黑人女性不同的人在软件工程职位上名列前茅的情况只有 11%,比表现最好的群体低 36%。
分析还发现,GPT 的性别和种族偏好因评估候选人的特定工作而异。 GPT 并不总是不利于任何一个群体,而是会根据具体情况选择赢家和输家。 例如,GPT 很少将与男性相关的名字列为人力资源和零售职位的最佳候选人,这两个职业历来由女性主导。 与每组具有男性独特姓名的简历相比,GPT 将西班牙裔女性独特姓名列为人力资源职位最佳候选人的可能性几乎是其两倍。 彭博社在使用不太广泛使用的 GPT-4 进行测试时还发现了明显的偏好,GPT-4 是 OpenAI 的新模型,该公司宣传该模型的偏见较少。
值得称赞的是,该团队还 在 GitHub 上发布了他们的结果,所以我们尝试复制它们。 我们的发现与彭博社的报道截然不同。
在我们深入了解我们的发现之前,先介绍一下我们所做的事情。
在他们的结果中,彭博社公布了 GPT-3.5 和 GPT-4 选择每个人群作为最佳候选人的比率。 彭博社分析师对每项工作进行了大量试验:例如,ChatGPT 被要求对人力资源专家工作的 8 份简历进行 1,000 次排名。 如果 ChatGPT 存在性别或种族偏见,那么每个组通常应该有 125 次成为首选(或者 12.5% 的时间,考虑到有 1000 个数据点)。
我们要去哪里? 统计迷可能已经注意到彭博社文章中的一个明显遗漏:统计显着性检验和 p 值。 为什么这很重要? 即使进行 1,000 次试验,完全公正的简历分类器也不会为您提供完全相等的比例,而是精确地挑选每组 125 次。 相反,纯粹的随机变化可能意味着一组被选择 112 次,另一组被选择 128 次,实际上不存在任何偏差。 因此,您需要运行一些测试来查看您获得的结果是偶然的还是因为确实存在某种模式。 运行测试后,p 值会告诉您一组特定的选择率与机会一致的概率,在本例中,与简历的随机(因此无偏见)排序一致。
我们计算了每组的 p 值1。 我们的发现与彭博社的报道截然不同。
彭博社研究出了问题的地方
考虑到我们业务的性质,我们首先考虑的是软件工程师。 以下是 Bloomberg 通过 GPT-4 对所有 8 个组运行软件工程简历的结果(标题为“obsfreq”的专栏)以及我们计算的 p 值。
A_M = 亚洲男性,A_W = 亚洲女性,等等。12.5% 是每个组中的候选人成为首选的预期比率(“expperc”)。 在 1000 名候选人中,每人 125 名(“expfreq”)。 最后,“obsfreq”是观察到的来自每个组的最佳候选者的频率,取自彭博社的结果。
按照惯例,您希望 p 值小于 0.05,以声明某些结果具有统计显着性 – 在这种情况下,这意味着结果由随机性引起的可能性小于 5%。 这个 p 值 0.2442 远高于此。 事实上,当软件工程师使用 GPT-3.5 时,我们也无法重现统计显着性。 根据彭博社的数据,ChatGPT 在评判软件工程师的简历时似乎没有种族偏见。2 结果似乎噪声多于信号。
然后,我们使用与上述相同的方法重新计算八个种族/性别组合的数字。 在下表中,您可以看到结果。 TRUE 意味着存在种族偏见。 FALSE 显然意味着不存在。 我们还分享了计算出的 p 值。 TL;DR 是,GPT-3.5 确实对人力资源专家和财务分析师表现出种族偏见,但对软件工程师或零售经理却没有。 最重要的是,GPT-4 不会对任何种族/性别组合表现出种族偏见。3
职业GPT 3.5(统计显着性? ‖ p 值)GPT 4(统计显着性? ‖ p 值)财务分析师TRUE ‖ 0.0000FALSE ‖ 0.2034 软件工程师 FALSE ‖ 0.4736FALSE ‖ 0.1658HR 专家TRUE ‖ 0.0000FALSE(但很接近) ‖ 0.0617零售经理FALSE ” 0.2229假 ” 0.6654
那太好了,对吧? 嗯,没那么快。 在我们认为 ChatGPT 能够胜任简历评判之前,我们想进行一次我们自己的测试,特别是针对软件工程师(因为这又是我们的专业领域)。 这次测试的结果并不令人鼓舞。
我们如何测试 ChatGPT
Interviewing.io 是一个匿名模拟面试平台,我们的用户与 FAANG 高级/职员/首席级工程师配对进行面试练习。 我们还将顶尖表现者与顶尖公司联系起来,无论他们在纸面上看起来如何。 在我们的一生中,我们主持过超过 10 万场技术面试,其中包括上述模拟面试和真实面试。 换句话说,我们有一堆关于软件工程师的有用的、指示性的历史绩效数据。4 因此我们决定使用该数据进行健全性检查。
设置
我们询问了 ChatGPT(GPT4,具体来说 gpt-4-0125-预览)对数千个 LinkedIn 个人资料进行评分,这些资料属于之前在 Interviewing.io 上练习过的人。 对于每个个人资料,我们要求 ChatGPT 为该人提供 1 到 10 之间的编码分数,其中 10 分的人将是前 10% 的编码员。 为了提高响应的质量,我们要求它首先给出推理,然后给出编码分数。
我们想在此明确表示,我们没有与 ChatGPT 分享任何性能数据,也没有与 ChatGPT 分享有关我们用户的任何信息——我们只是要求它对公开的 LinkedIn 个人资料做出价值判断。 然后我们将这些价值判断与我们的数据进行比较。
ChatGPT 的表现如何
ChatGPT 所说的内容与编码员在真实技术屏幕上的表现之间存在相关性。 该工具的性能比随机猜测要好……但也好不了多少。 正确看待这些结果总体而言,47% 的编码员通过了筛选。 ChatGPT 分数可以将它们分为两组:一组有 45% 的机会,一组有 50% 的机会。 因此,它为您提供了有关某人是否会成功的更多信息,但不多。
以下是查看 ChatGPT 性能的两种更精细的方法。 第一个是修改后的校准图,第二个是 ROC 曲线。
校准图
在此图中,我们从 ChatGPT 中获取每个预测概率(例如 0.4112),并将其分配给 10 个等距十分位数之一。 Decile 1 是概率最低的 10% 的配置文件。 Decile 10 是概率最高的 10% 的人。
然后,对于每个十分位数,我们绘制了那些在面试中表现良好的候选人的实际概率(即,其中有多少人实际上通过了 Interviewing.io 上的面试)。 正如你所看到的,情节有些混乱——对于 ChatGPT 提出的所有十分位数,这些候选人实际上通过了大约一半的时间。 理想的图(“一个优秀的模型”)将具有更陡的斜率,底部十分位数的通过次数比顶部十分位数要少得多。
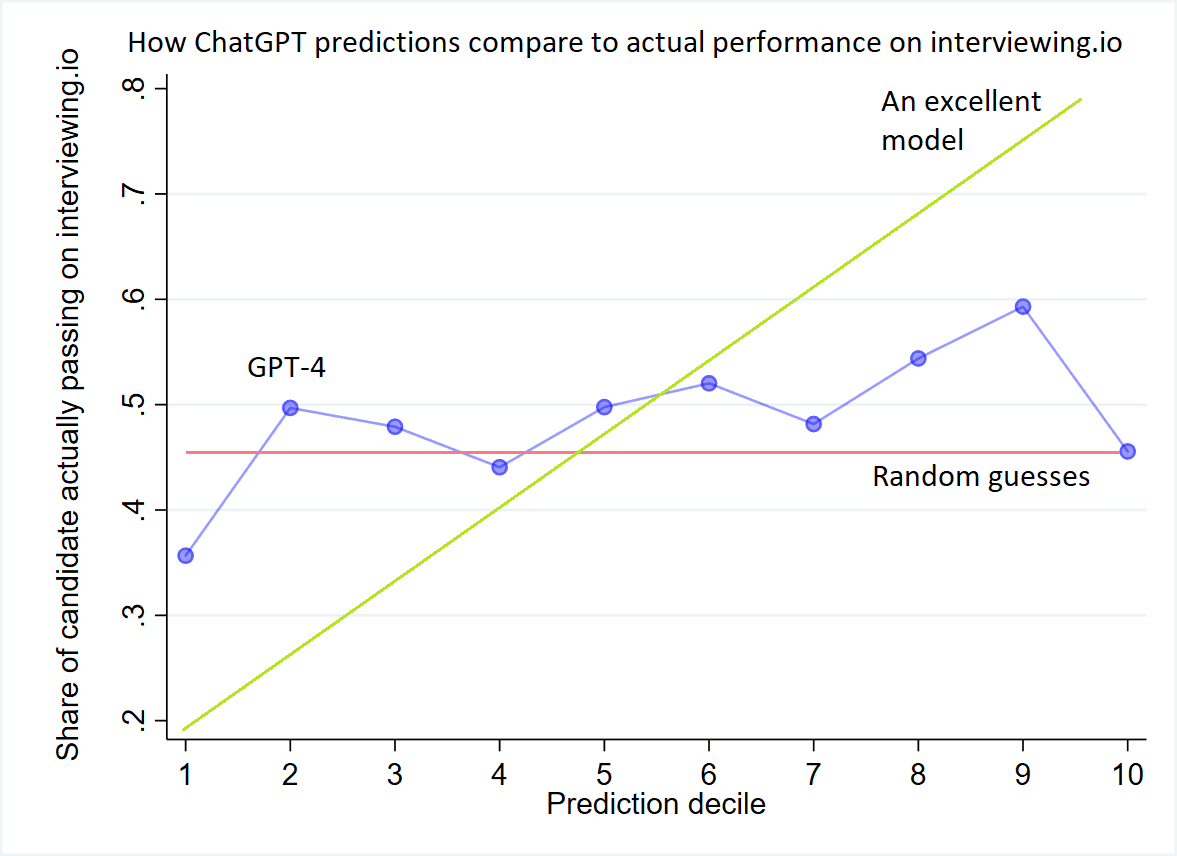
我们要求 GPT-4 来判断数千份 LinkedIn 个人资料,这些资料属于之前在 Interviewing.io 上练习过的人。 然后我们将其预测分为十分位数(10%),并与这些用户的实际表现进行比较。 一个伟大的模型在第一个十分位中表现不佳,然后急剧而稳定地改善。
ROC曲线
判断 ChatGPT 在此任务中表现的另一种方法是查看 ROC 曲线。 该曲线绘制了模型的真阳性率与假阳性率的关系图。 这是判断 ML 模型准确度的标准方法,因为它可以让观察者看到它在不同可接受的误报率下的表现——例如,对于癌症诊断,您可能会接受非常高的误报率。 对于工程师招聘,你可能不会!
与 ROC 曲线相关的是 AUC,即曲线下面积。 完美的模型对于每种可能的误报率都具有 100% 的真阳性率,因此曲线下面积将为 1。与猜测基本相同的模型的真阳性率将等于误报率 (曲线下面积 = 0.5)。 考虑到这一点,这是 ChatGPT 判断简历的 ROC 曲线和 AUC — 总体 AUC 约为 0.55,仅比随机猜测好一点。

我们要求 GPT-4 来判断数千份 LinkedIn 个人资料,这些资料属于之前在 Interviewing.io 上练习过的人。 它的表现仅仅比猜测好一点。
因此,无论你如何衡量,虽然 ChatGPT 在判断工程师的个人资料时似乎没有种族偏见,但它也不是特别擅长这项任务。
ChatGPT 对非传统候选人有偏见
为什么 ChatGPT 在这项任务上表现不佳? 也许是因为简历中一开始就没有那么多信号。 但还有另一种可能的解释。
几年前,我进行了一项实验,对一堆简历进行匿名处理,并让招聘人员尝试猜测哪些候选人是优秀的。 他们在这项任务上做得非常糟糕,几乎和随机猜测一样。 毫不奇怪,他们倾向于过度索引包含顶级公司或名校的简历。 在我的候选人数据集中,我碰巧有很多非传统的优秀候选人——他们是优秀的工程师,但没有就读于排名靠前的学校或在顶级公司工作。 这让招聘人员陷入了困境。
看起来 ChatGPT 也发生了同样的事情,至少部分如此。 我们回顾了 ChatGPT 如何对待 LinkedIn 个人资料中拥有顶级学校的候选人与没有的候选人。 事实证明,ChatGPT 一直高估了简历中拥有顶尖学校和顶尖公司的工程师的通过率。 我们还发现,ChatGPT 一贯低估简历中没有这些精英“证书”的候选人的表现。 这两个差异在统计上都是显着的。 在下图中,您可以准确地看到 ChatGPT 在每种情况下高估和低估的程度。

值得赞扬的是,我们在顶级公司方面没有发现同样的偏见,这很有趣,因为根据我们的经验,在顶级公司工作过会带来一些预测信号,而某人在哪里上学则不会带来太多预测信号。
ChatGPT 不是种族主义者,但其偏见仍然使其在招聘方面表现不佳
在招聘中,我们经常谈论无意识的偏见。 虽然它不再流行,但公司历来花费数万美元进行无意识偏见培训,旨在阻止招聘人员根据候选人的性别和种族做出决定。 与此同时,招聘人员接受的培训显示出一种不同的、有意识的偏见:积极从精英学校和顶级公司中挑选候选人。
ChatGPT 中似乎也记录了对未就读于顶级学校的候选人的同样有意识的偏见。
这个决定是理性的——在没有更好的信号的情况下,你必须使用代理,而这些代理似乎和任何代理一样好。 不幸的是,正如您从这些结果(以及我们过去所做的其他研究中看到的那样;完整列表请参阅脚注)5),它不是特别准确……而且它绝对不够准确,无法编入我们的人工智能工具中。
在招聘人员工作机会薄弱的市场中, 招聘人员数量的减少正在处理比以前更多的申请人 并且比以往任何时候都更有压力做出上述快速决策,而企业正在将人工智能视为一种诱人且富有成效的成本削减措施6,我们正处于相当危险的境地。
几个月前,我们发表了一篇长文,名为“为什么人工智能不能做招聘”。 这篇文章的主要两点是:1)很难从简历中提取信号,因为一开始就没有太多信息;2)即使可以,你也需要专有的性能数据来训练人工智能——没有该数据表明您正在进行美化的关键字匹配。
不幸的是,大多数(如果不是全部)声称可以帮助招聘人员做出更好决策的人工智能工具和系统没有此类数据,并且 1) 要么构建在 GPT(或其类似物之一)之上,而无需进行微调或 2) 是伪装成人工智能的美化关键字匹配器,或两者兼而有之。
尽管人类招聘人员并不是特别擅长判断简历,尽管我们作为一个社会还没有一个很好的解决方案来解决有效的候选人过滤问题,但很明显,现成的人工智能解决方案并不是神奇的。我们正在寻找的药丸——它们和人类一样有缺陷。 他们只是更快、更大规模地做错事。
脚注:
1713292669
#ChatGPT #不是种族主义者 #但在招聘方面却很糟糕
2024-04-16 18:08:10


:quality(70):focal(514x399:524x409)/cloudfront-eu-central-1.images.arcpublishing.com/irishtimes/SDVWOEEDWE4XT2FB2NCCQH5Q24.jpg)
:quality(70)/cloudfront-eu-central-1.images.arcpublishing.com/irishtimes/4K447H4VFZNPHNMWOD4WELRPFM.jpg)







